Abstract
We present Extreme Bandwidth Extension Network (EBEN), a Generative Adversarial network (GAN) that enhances audio measured with body-conduction microphones. This type of capture equipment suppresses ambient noise at the expense of speech bandwidth, thereby requiring signal enhancement techniques to recover the wideband speech signal. EBEN leverages a multiband decomposition of the raw captured speech to decrease the data time-domain dimensions, and give better control over the full-band signal. This multiband representation is fed to a U-Net-like model, which adopts a combination of feature and adversarial losses to recover an enhanced audio signal. We also benefit from this original representation in the proposed discriminator architecture. Our approach can achieve state-of-the-art results with a lightweight generator and real-time compatible operation.
ICASSP Paper
Motivation of our work
In-ear
(quiet conditions)
Reference
(quiet conditions)
In-ear
(85dB noise)
Reference
(85dB noise)
Listen to in-ear, reference and enhanced audios
In-ear
(simulated)
EBEN
(ours)
Reference
HifiGAN v3
Kuleshov
Seanet
Streaming Seanet
Inspect corresponding spectrograms by yourself !

Funny experiments
In this example, we trained a bandwidth extension model on a given language and inferred it on degraded audio in another language. In the obtained enhanced audio, you'll notice a strong "accent", based on the language the model was trained for. Speech quality metrics do not penalize this behavior and give similar scores to models trained in the same language as inference.
Enhanced
(by a model trained with english content)
Reference
(french)
Enhanced
(by a model trained with french content)
Reference
(english)
Perceptual Evaluation
In order to evaluate the performance of the trained models, we performed two MUSHRA listening tests with 88 (resp. 82) participants on sound quality and ease of understanding. Each participant had to listen to 7 different audios enhanced with 5 different approaches (+reference +low anchor + original corrupted audio). For each experiment, the MUSHRA procedure consisted in giving a note between 0 and 100. The results from this study are found below.
Speech quality metrics on test dataset
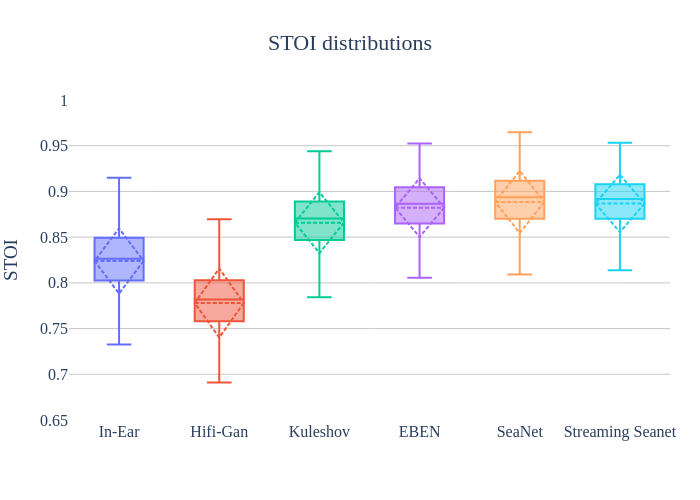
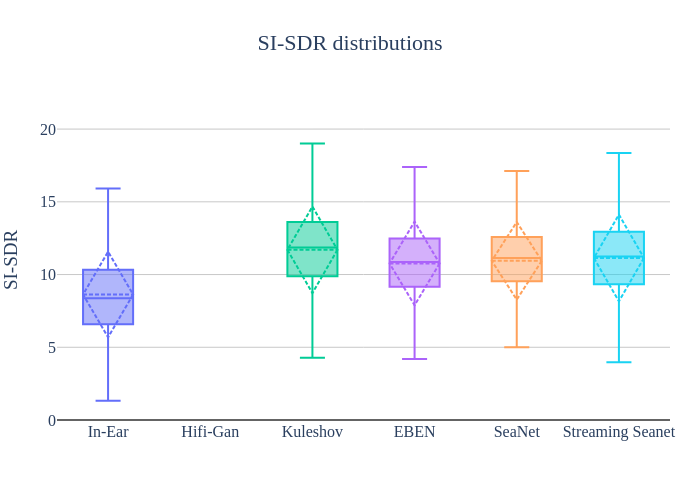

Frugality indicators
| Approach | Generator | Discriminators |
|---|---|---|
| Audio U-net | 71.0M | 0 |
| Hifi-GAN v3 | 1.5M | 70.7M |
| Seanet | 8.3M | 56.6M |
| Streaming-Seanet | 0.7M | 56.6M |
| EBEN | 1.9M | 27.8M |
| Approach | Inference mode latency for a single one-second sample on a NVIDIA GeForce RTX 2080 Ti |
|---|---|
| Audio U-net | 37.5ms |
| Hifi-GAN v3 | 3.1ms |
| Seanet | 13.1ms |
| Streaming-Seanet | 7.5ms |
| EBEN | 4.3ms |
| Approach | Inference mode maximum memory allocation for a single one-second sample on a NVIDIA GeForce RTX 2080 Ti |
|---|---|
| Audio U-net | 1117.3 MB |
| Hifi-GAN v3 | 22.2 MB |
| Seanet | 89.2 MB |
| Streaming-Seanet | 10.9 MB |
| EBEN | 20.0 MB |
EBEN hyperparameters
| Name | Learning rate | Betas |
|---|---|---|
| Adam | 3e-4 | (0.5,0.9) |
| Batch size | Temporal length | Sampling rate |
|---|---|---|
| 16 | 2 sec | 16 kHz |
| Bands number (=decimation) | Kernel size | Beta |
|---|---|---|
| 4 | 32 | 9 |
| Reconstructive | Adversarial |
|---|---|
| 100 | 1 |
| Generator | Discriminators |
|---|---|
| LeakyReLU(negative_slope=0.01) | LeakyReLU(negative_slope=0.2) |