Deep learning for speech enhancement applied to radio communications using non-conventional sound capture devices
PhD defense — Julien Hauret
September 12, 2025 - Cnam Paris - Laussédat Amphitheater
Supervisor: Éric Bavu - Co-supervisor: Thomas Joubaud



Context
Context
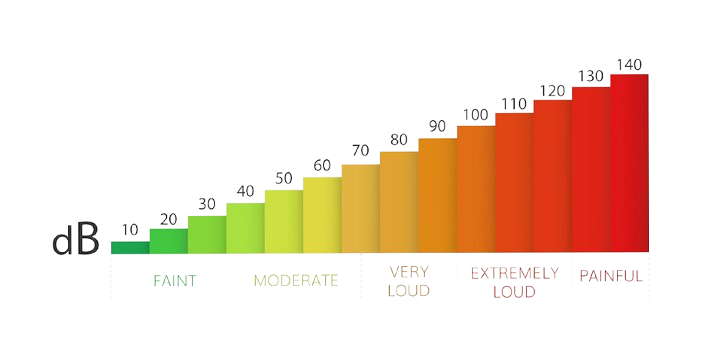
How to extract voice in noisy environments ? ⇒ body-conduction microphones (BCM)
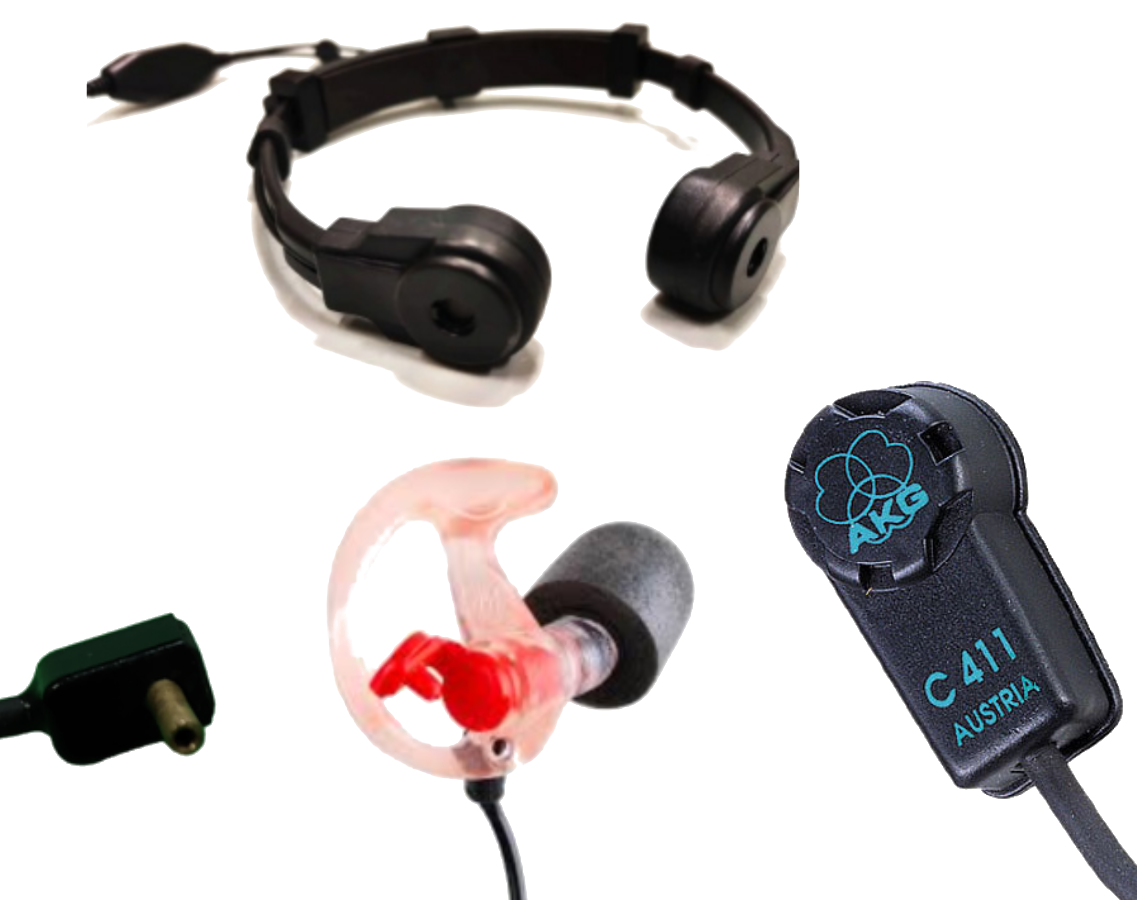
First BCM

Current BCM
Chemical Research on BCM
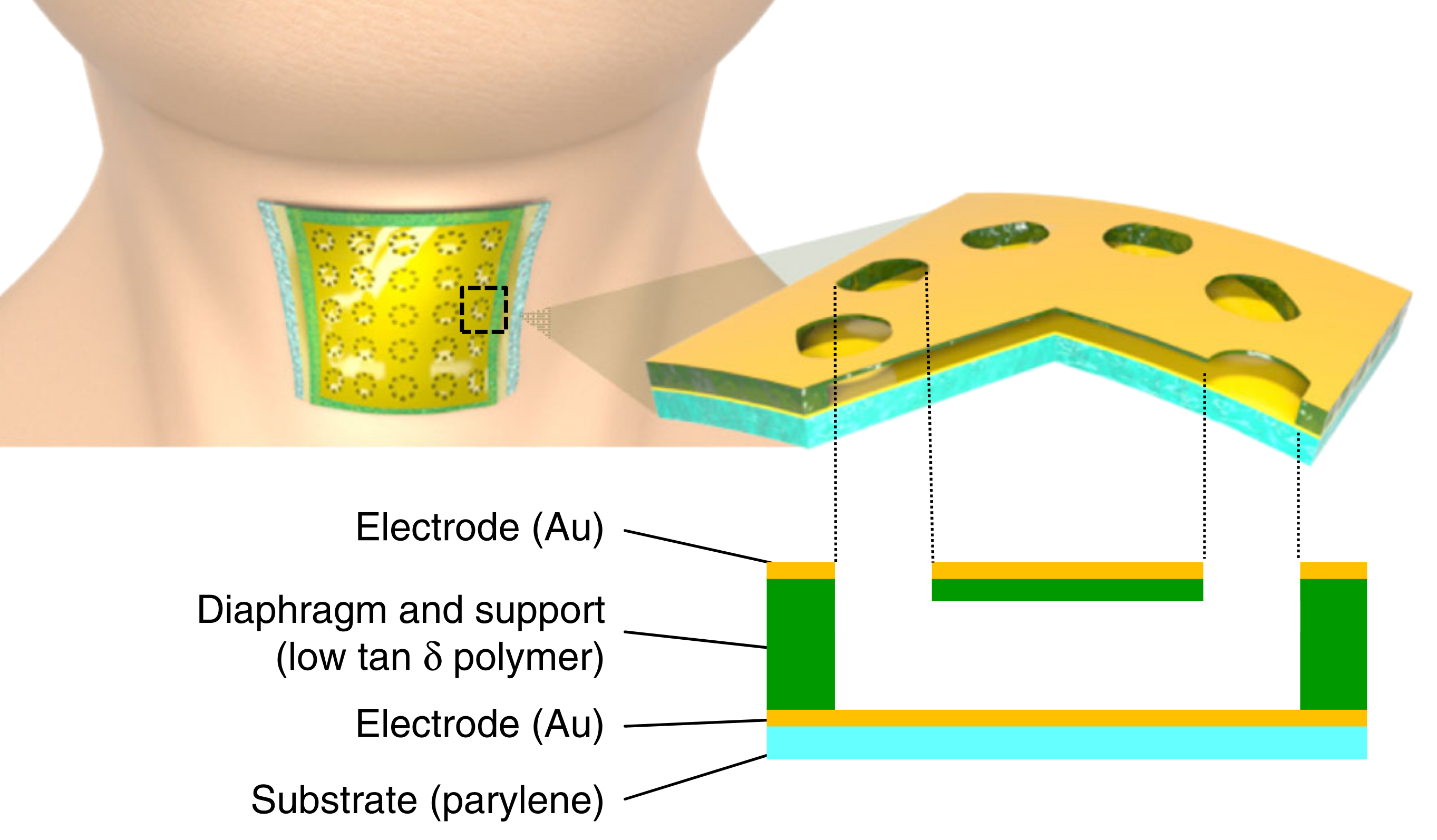
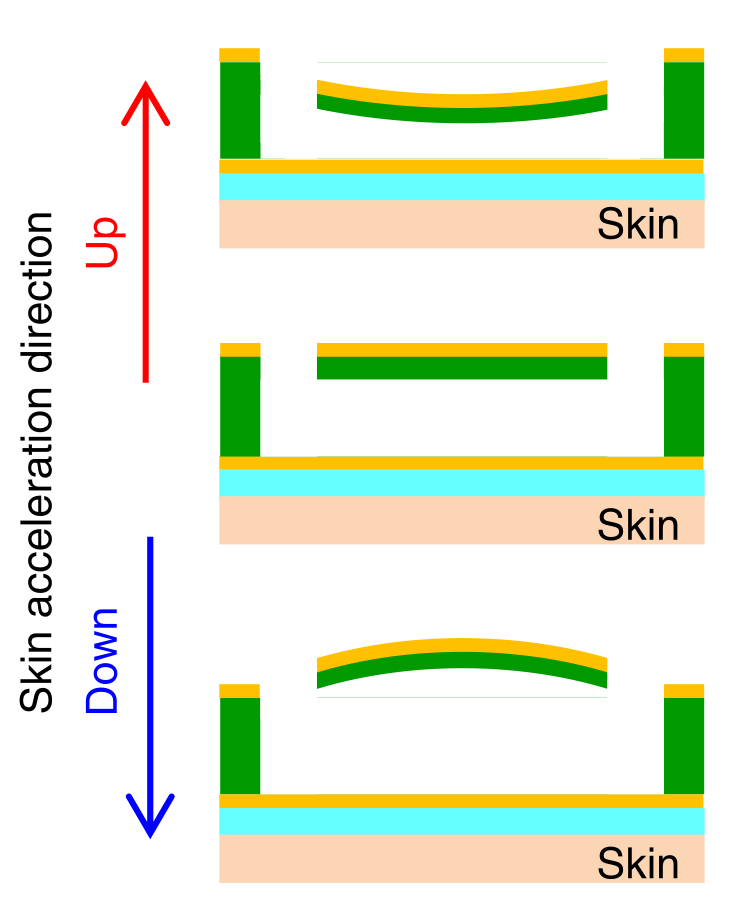
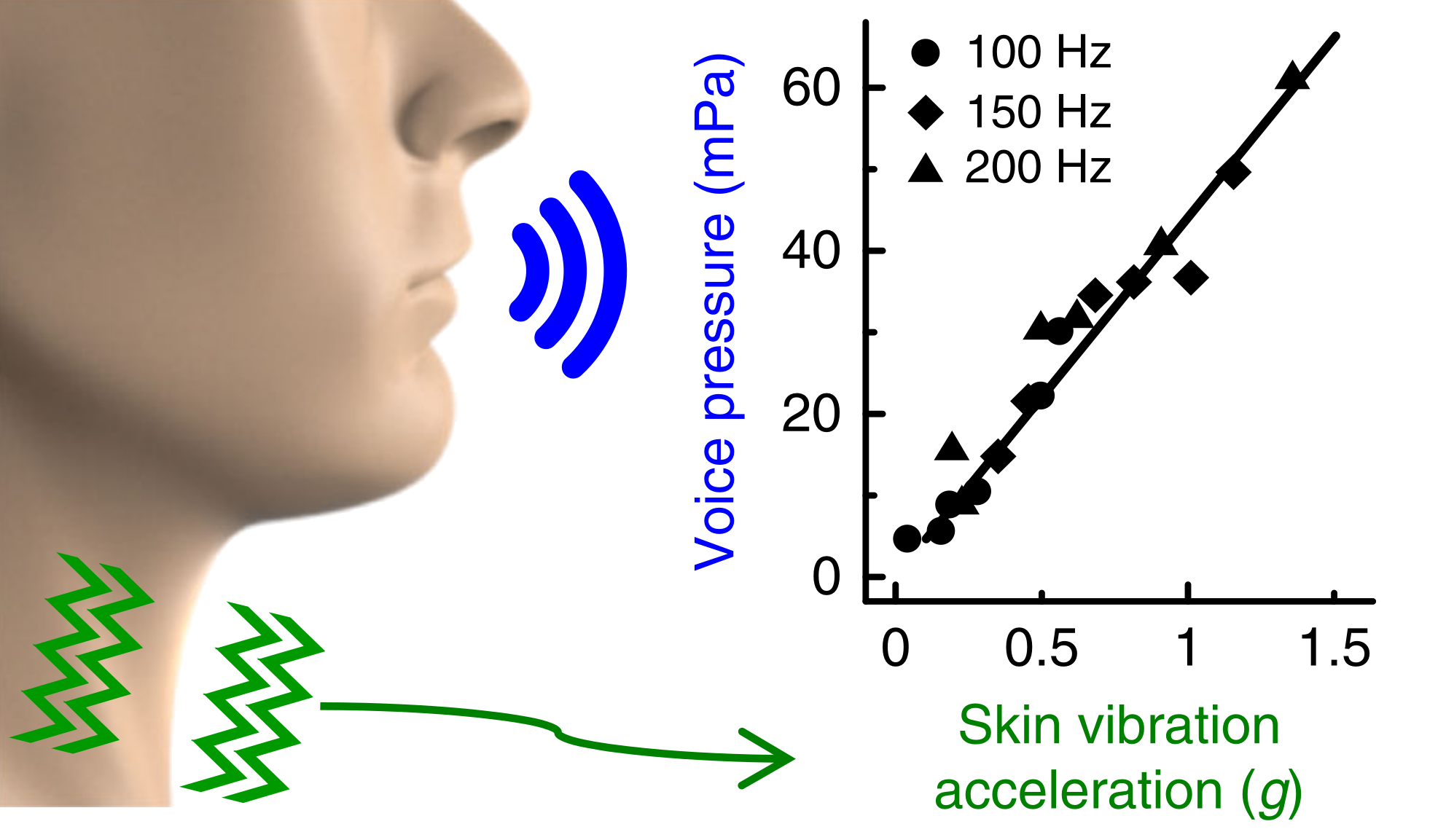
Mechanics Research on BCM
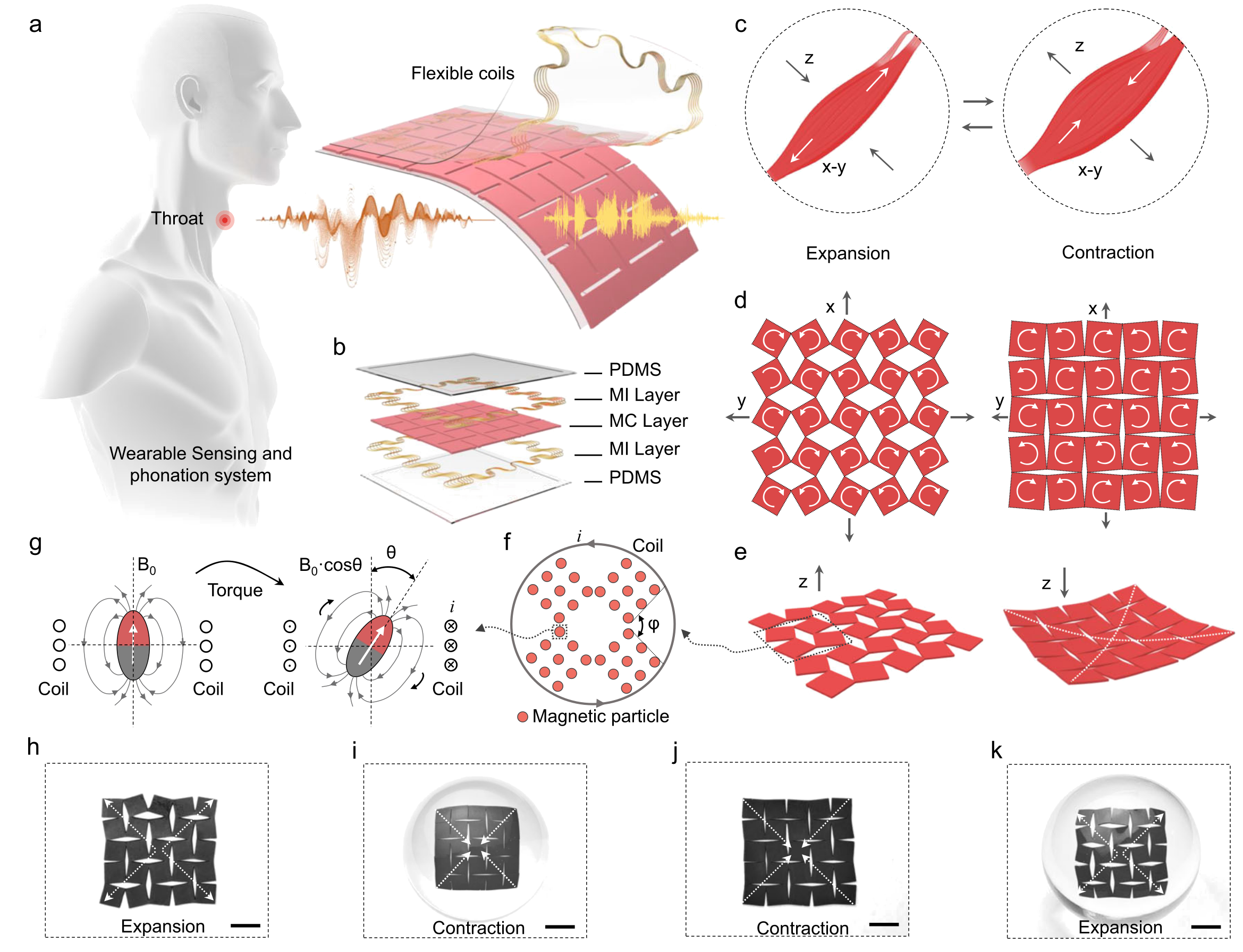
Integration in wearables

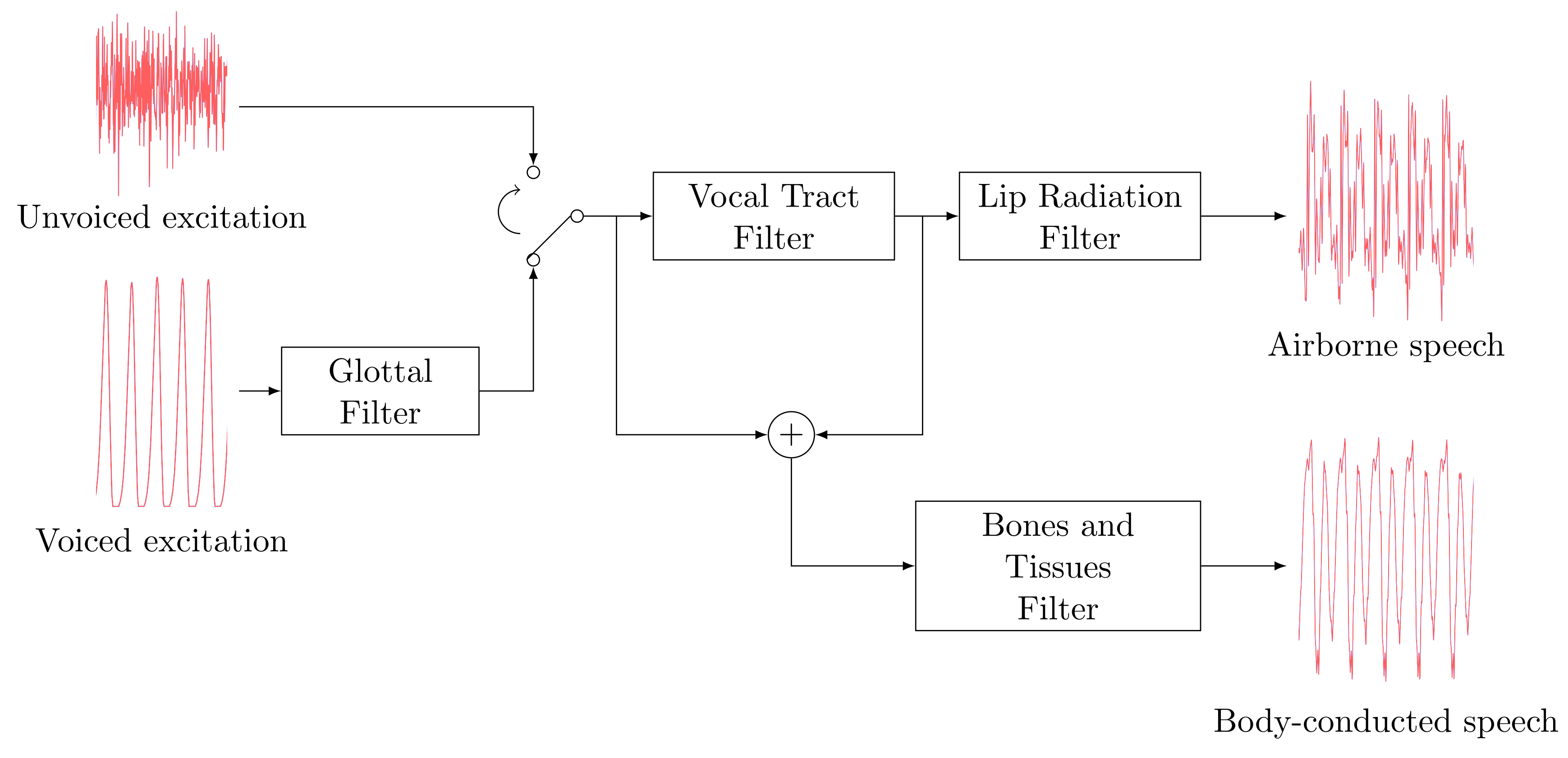
Source-filter model
In-ear capture
Spectrogram in silence
Spectrogram in 85dB noise
First Takeaway
- BCMs are not new but sensor design is still evolving
- Inherently robust to environmental noise
- Loss of high-frequency components reduces quality and intelligibility
- Advanced enhancement algorithms are needed
Path to Deep Learning
Families of Speech Enhancement Algorithms
enhancement
algorithm
processing
based
processing
based
learning
based
learning
based
Difference between discriminative and generative training
 ℒadv
ℒrec
ℒadv
ℒrec
Generative Adversarial Networks
Intuition on building $g_{\theta}$ and $d_{\phi}$ for BCM enhancement
Building the generator $g_{\theta}$
- Focus on low-frequency cues
- Leverage the structure of x to construct ŷ
- Fast, lightweight and real-time compatible
- Let the gradient flow
Building the discriminator $d_{\phi}$
- Capture hierarchical patterns in audio
- Cover all frequency ranges
- Let the gradient flow
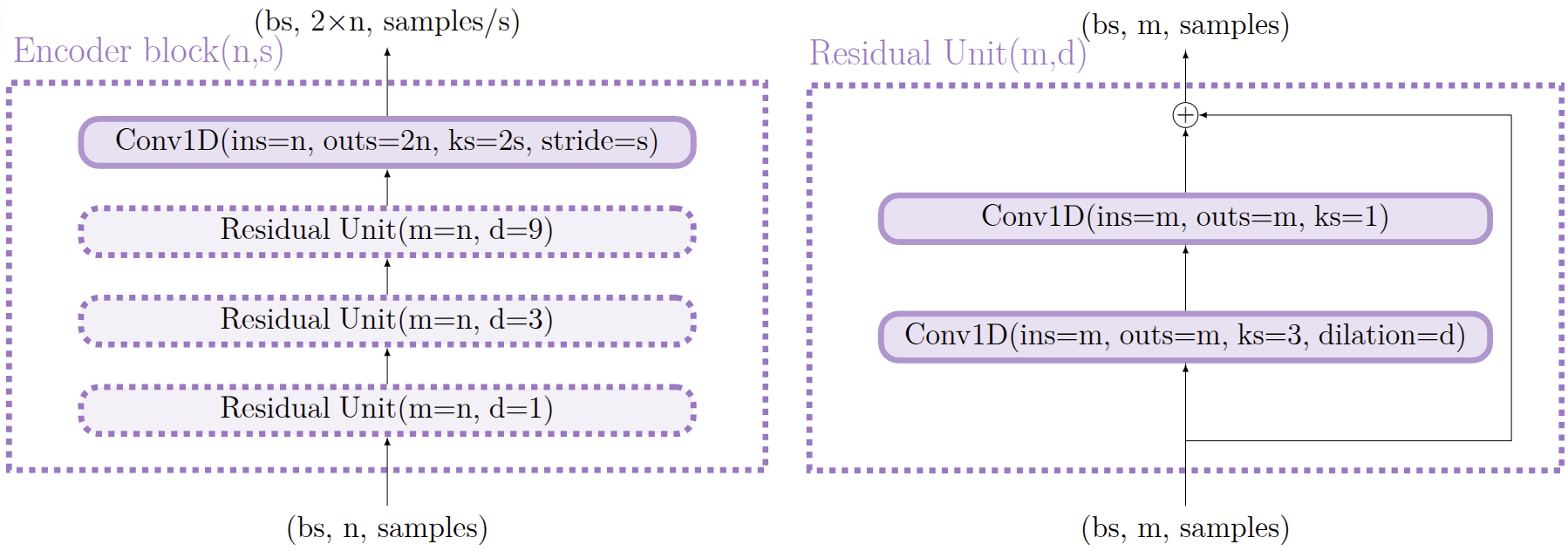
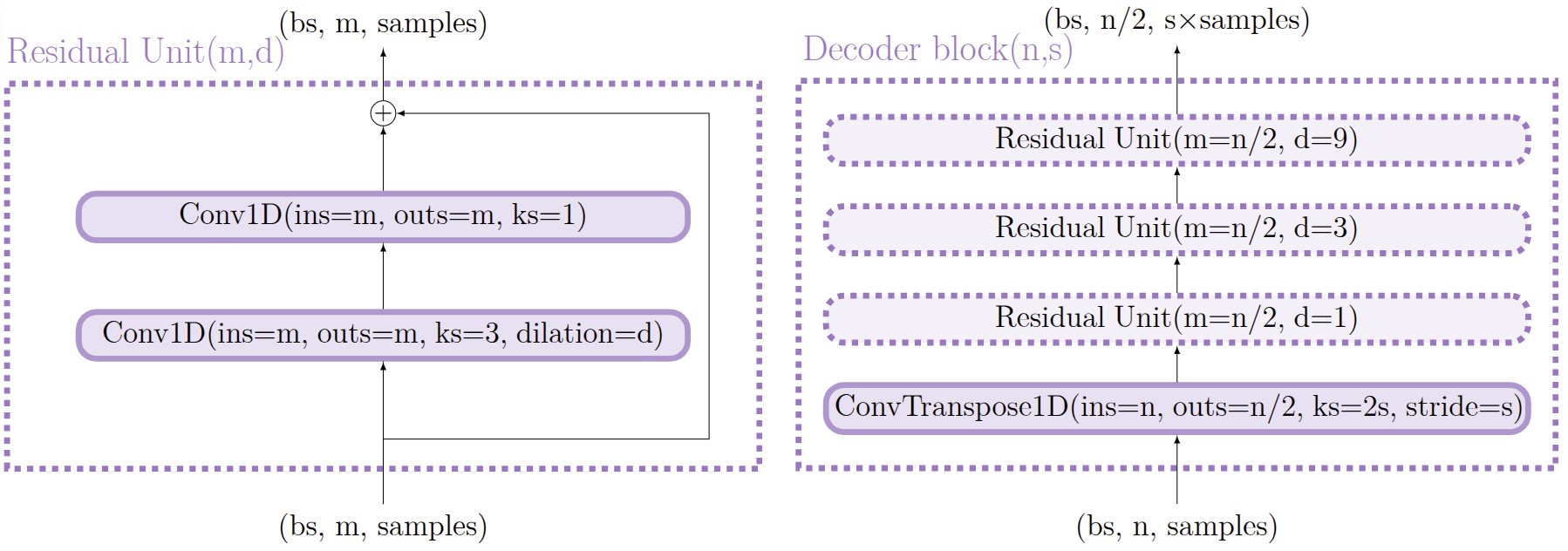
EBEN: Extreme Bandwidth Extension Network
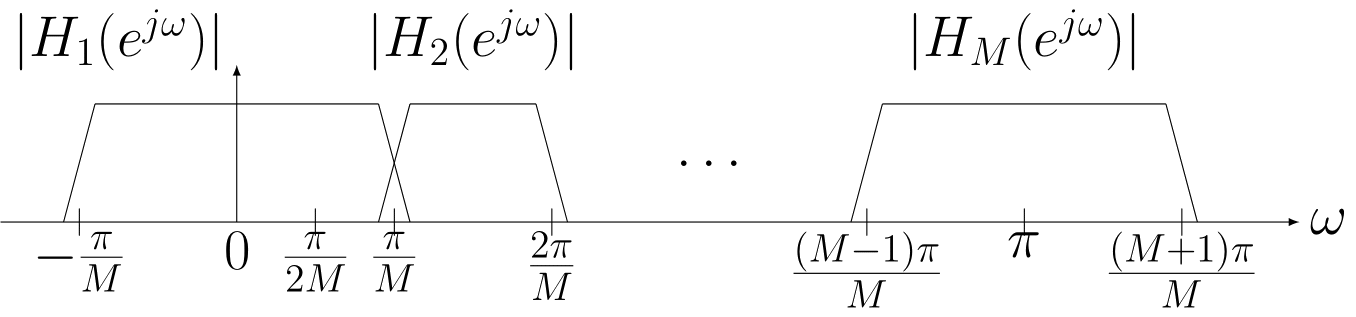
Pseudo Quadrature Mirror Filters pipeline
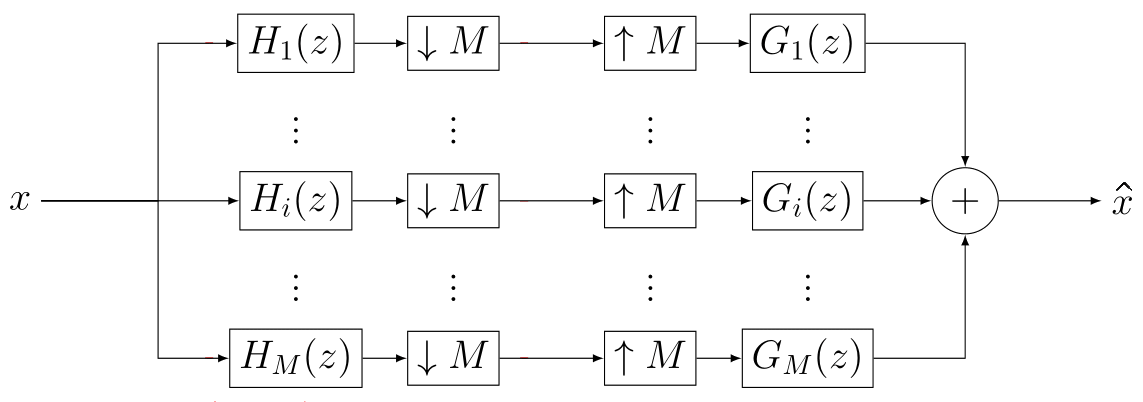
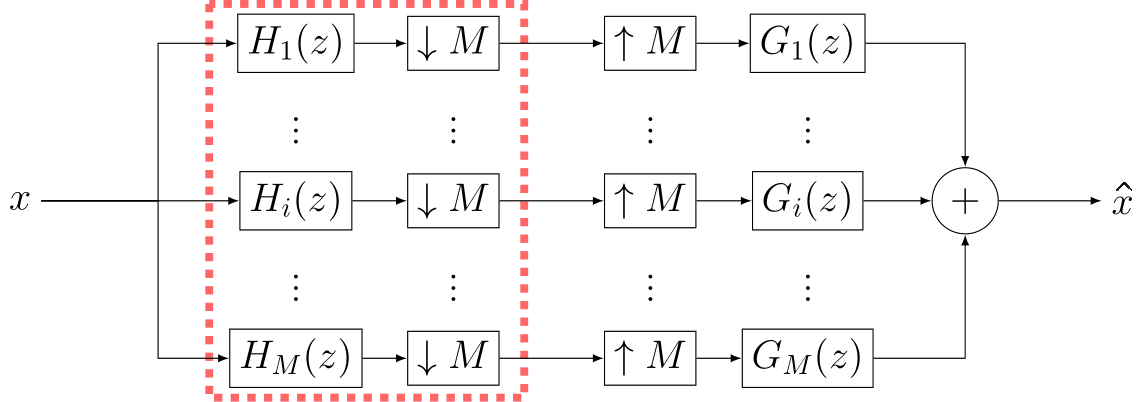
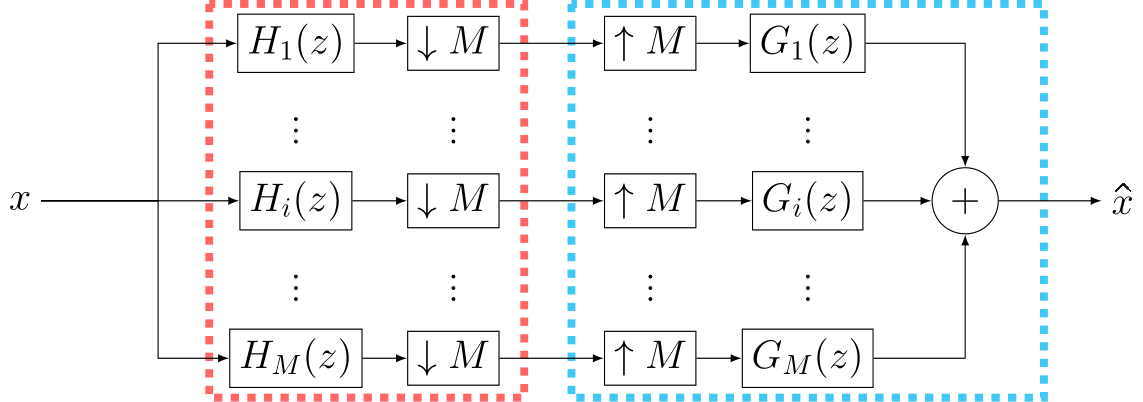
Pseudo Quadrature Mirror Filters bank
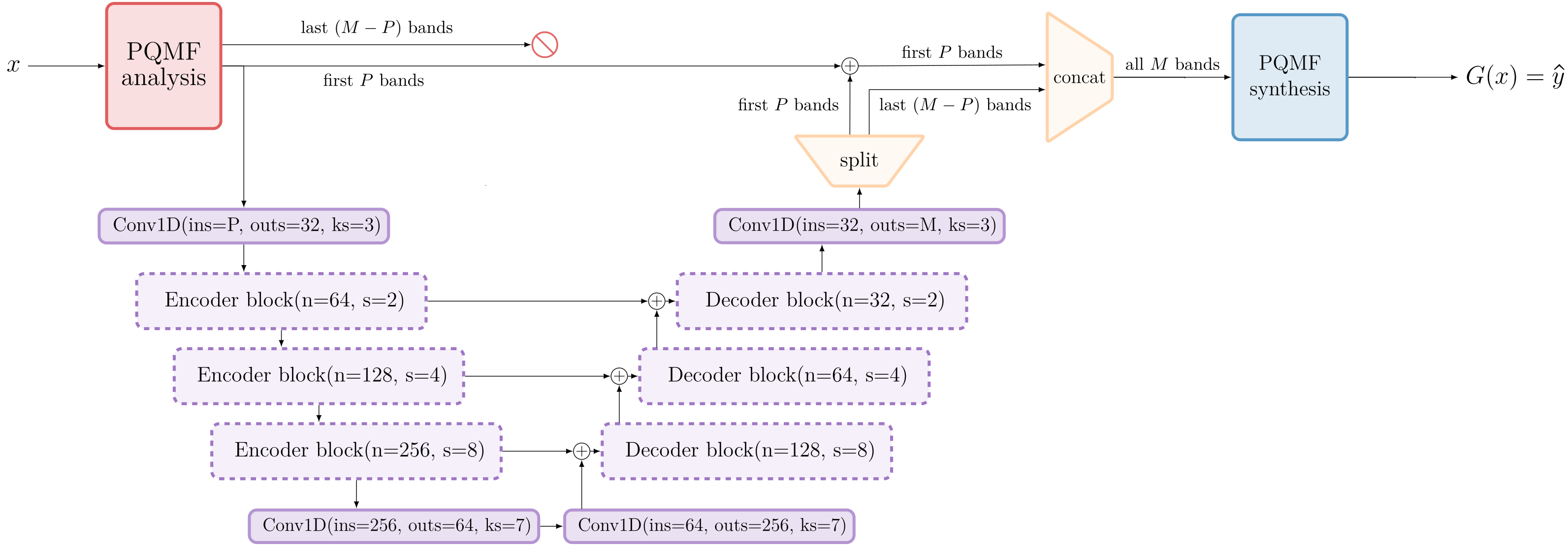
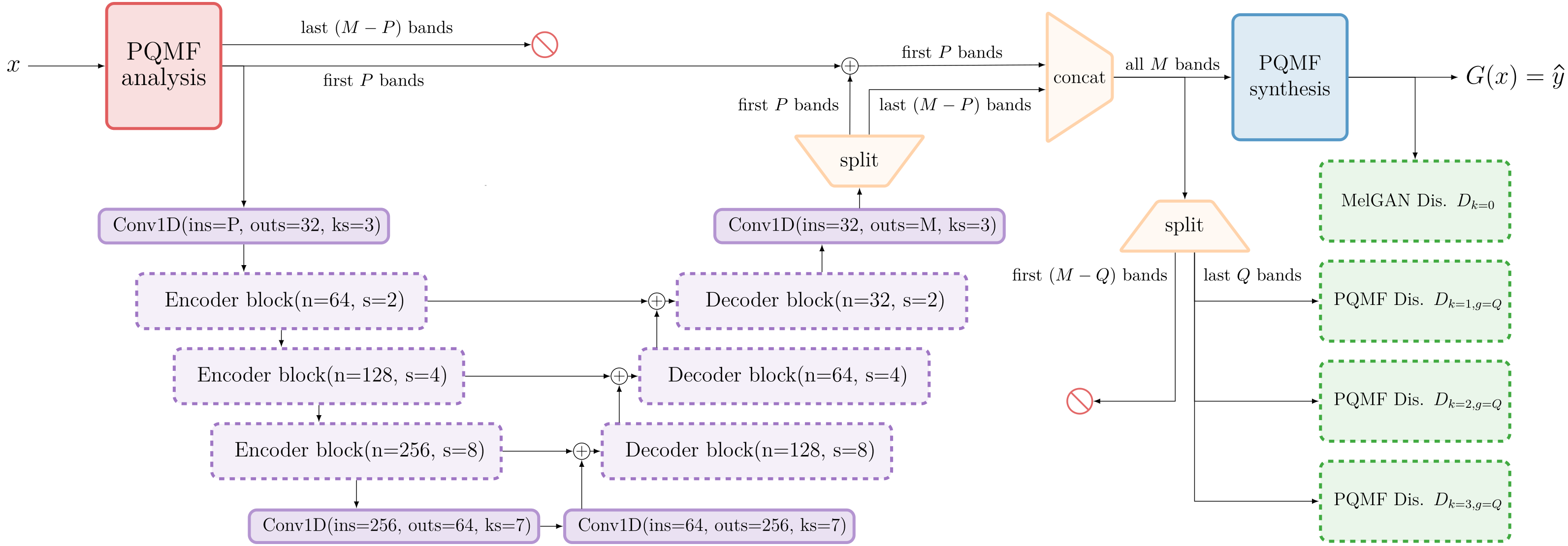
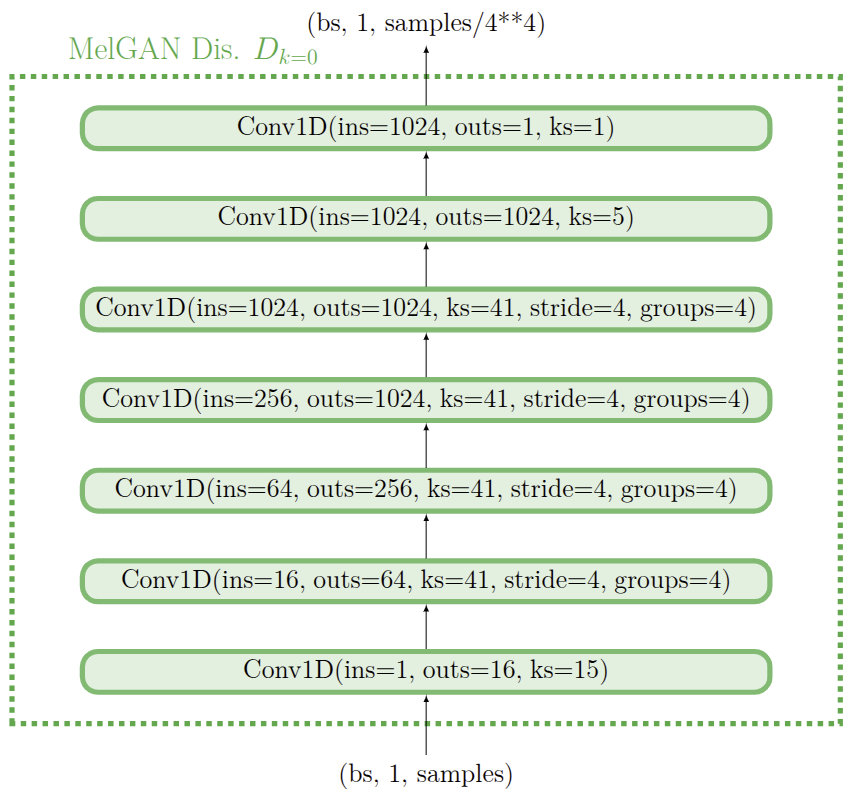
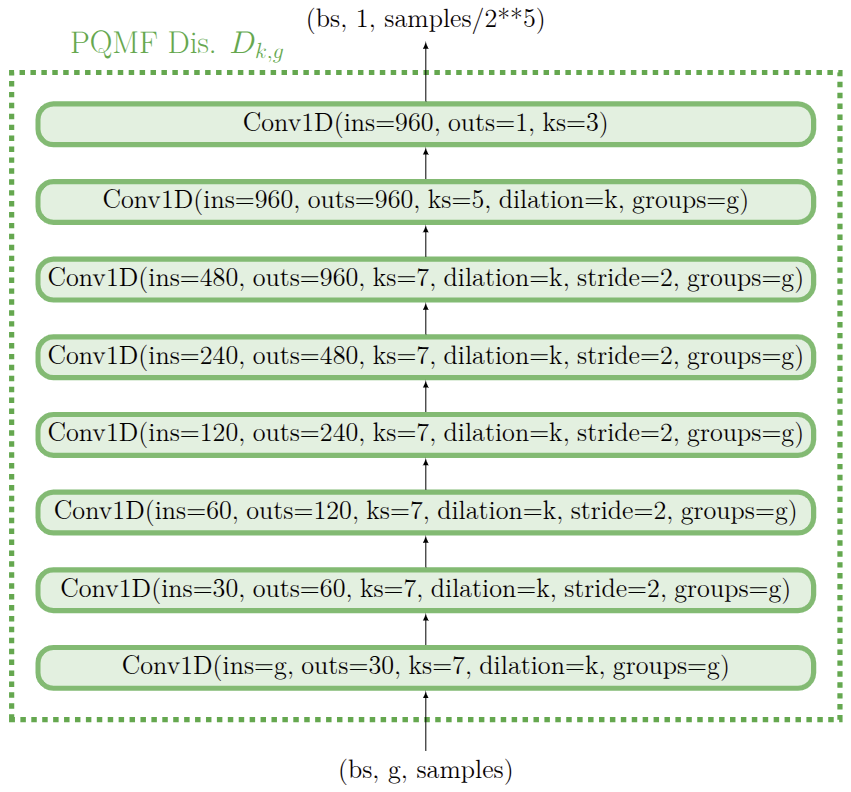
Loss Functions
\[ \mathcal{L_D}= \mathbb{E}_y\left[ \frac{1}{K} \sum_{k \in [0,3]} \frac{1}{T_{k,L_k}} \sum_t \max(0,1-D_{k,t}(y))\right] + \mathbb{E}_x\left[ \frac{1}{K} \sum_{k \in [0,3]} \frac{1}{T_{k,L_k}} \sum_t \max(0,1+D_{k,t}(G(x)))\right] \] (1) Discriminator loss
\[ \mathcal{L}_\mathcal{G}^{adv}= \mathbb{E}_x\left[ \frac{1}{K} \sum_{k \in [0,3]} \frac{1}{T_{k,L_k}} \sum_t \max(0,1-D_{k,t}(G(x)))\right] \] (2) Generator adversarial loss
\[ \mathcal{L}_\mathcal{G}^{feat}= \mathbb{E}_x \left[ \frac{1}{K} \sum_{\substack{k \in [0,3] \\ l \in [1,L_k [ }} \frac{1}{T_{k,l}F_{k,l}} \sum_t \frac{\left\| D_{k,t}^{(l)}(y)-D_{k,t}^{(l)}(G(x)) \right\|_{L_1}}{ \mathrm{mean}(D_{k,t}^{(l)}(G(x)))}\right] \] (3) Generator feature loss
\[ \mathcal{L}_\mathcal{G}^{spec} = \mathbb{E}_{x, y} \left[ \sum_{\substack{f_r \in \{512, 1024, 2048\} \\ h_r \in \{50, 120, 240\} \\ w_r \in \{240, 600, 1200\}}} \left\| \Psi\left(\mathrm{STFT}_{f_r, h_r, w_r}(y)\right) - \Psi\left(\mathrm{STFT}_{f_r, h_r, w_r}(G(x))\right) \right\|_{L_1} \right] \] (4) Generator spectral loss
What about DATA ?
Deep learning triplet
Simulated data
Degradation
Simulation process
Qualitative results: comparison
Objective metrics
models trained and tested on
in-ear like Librispeech
| Speech | Audio | eSTOI | Noresqa-MOS |
|---|---|---|---|
| Simulated In-ear | 0.83 | 2.57 | |
| Audio U-net | 0.87 | 2.59 | |
| Hifi-GAN v3 | 0.78 | 3.70 | |
| Streaming Seanet | 0.89 | 3.91 | |
| Seanet | 0.89 | 4.25 | |
| EBEN (ours) | 0.89 | 4.02 |
MUSHRA comparative evaluation
Frugality indicators
| Speech | \[P_{gen}\] | \[P_{dis}\] | \[\tau~\textrm{(ms)}\] | \[\delta~\textrm{(MB)}\] |
|---|---|---|---|---|
| Audio U-net | 71.0 M | \[\emptyset\] | 37.5 | 1117.3 |
| Hifi-GAN v3 | 1.5 M | 70.7 M | 3.1 | 22.2 |
| Streaming Seanet | 0.7 M | 56.6 M | 7.5 | 10.9 |
| Seanet | 8.3 M | 56.6 M | 13.1 | 89.2 |
| EBEN (ours) | 1.9 M | 27.8 M | 4.3 | 20 |
Thank you for your attention
julien.hauret@lecnam.net
What about REAL DATA ?
Objective metrics
models trained on in-ear like Librispeech
| Test set | eSTOI | Noresqa-MOS |
|---|---|---|
| In-domain (simulation) | 0.89 | 4.02 |
| Real signals | 0.51 | 3.82 |
- Enhance the simulation process
- Record a body-conducted speech dataset
Vibravox Dataset
Data









45 hours
Ambisonic sphere

Noise Level Summary
| Subset | Weighting | Leq [dB] | Lmin [dB] | Lmax [dB] |
|---|---|---|---|---|
speech-noisy (3 hours) |
Linear | 94.1 | 63.3 | 108.7 |
| A | 90.8 | 57.7 | 106.6 | |
speechless-noisy (8 hours) |
Linear | 89.6 | 31.9 | 103.2 |
| A | 88.0 | 17.9 | 104.4 |
Consent form
Vibravox sensors
Recording UI
Filtering
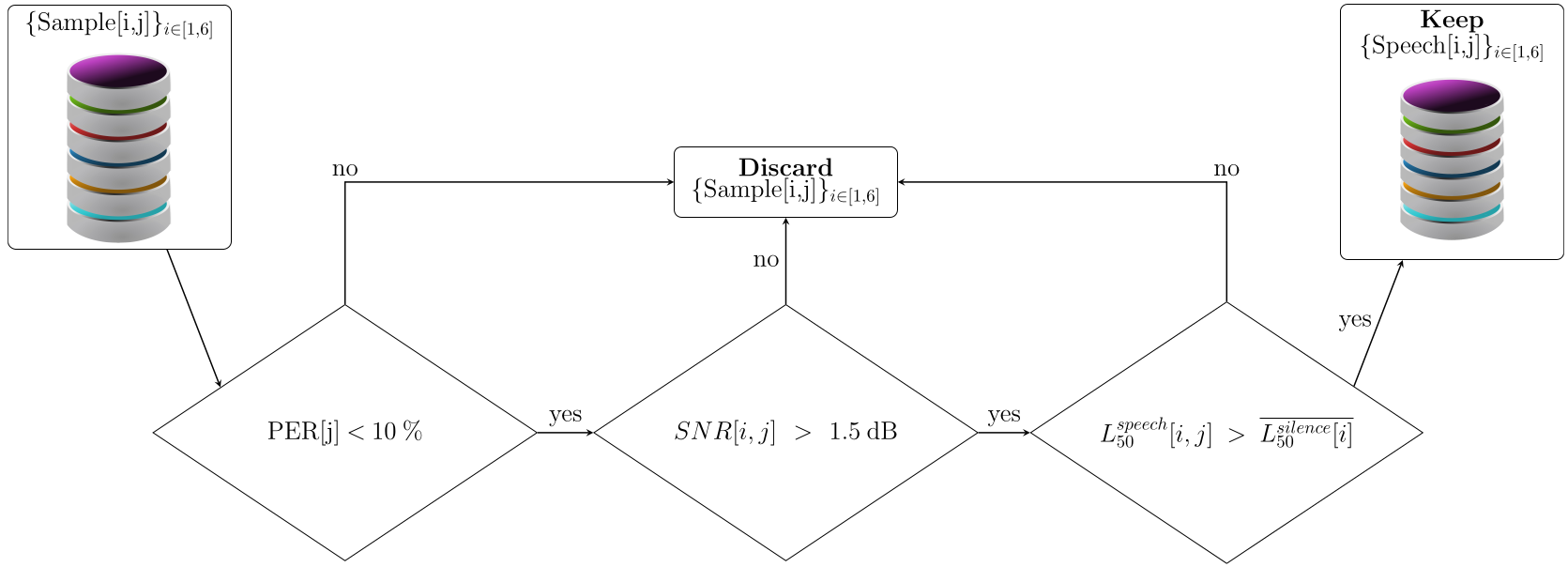
Coherence with Airborne Microphone
Results on real data
Testing of EBEN models on
speech-clean
| Sensor | Configuration | eSTOI | Noresqa-MOS |
|---|---|---|---|
| Forehead | Raw signal | 0.731 | 3.760 |
| EBEN (M=4, P=4, Q=4) | 0.855 | 4.250 | |
| Soft In-ear | Raw signal | 0.752 | 3.315 |
| EBEN (M=4, P=2, Q=4) | 0.868 | 4.331 | |
| Rigid In-ear | Raw signal | 0.782 | 3.392 |
| EBEN (M=4, P=2, Q=4) | 0.877 | 4.285 | |
| Throat | Raw signal | 0.677 | 3.097 |
| EBEN (M=4, P=2, Q=4) | 0.834 | 3.862 | |
| Temple | Raw signal | 0.602 | 2.905 |
| EBEN (M=4, P=1, Q=4) | 0.763 | 3.632 |
Testing of EBEN models on
speech-noisy
| Sensor | Initialization | Squim-eSTOI | Noresqa-MOS |
|---|---|---|---|
| Forehead | Raw signal | 0.901 | 3.85 |
| Tested from pretrained* | 0.949 | 4.08 | |
| Trained† from scratch | 0.949 | 4.14 | |
| Trained† from pretrained* | 0.971 | 4.20 | |
| Rigid In-ear | Raw signal | 0.751 | 3.47 |
| Tested from pretrained* | 0.812 | 3.73 | |
| Trained† from scratch | 0.876 | 3.51 | |
| Trained† from pretrained* | 0.873 | 3.80 | |
| Throat | Raw signal | 0.942 | 3.71 |
| Tested from pretrained* | 0.969 | 4.05 | |
| Trained† from scratch | 0.978 | 3.87 | |
| Trained† from pretrained* | 0.971 | 3.98 |
speech-clean† trained on synthetically mixed
speech-clean + speechless-noisy
speech-noisy samples
Noisy headset
Headset enhanced (Sepformer)
Noisy Throat
Throat enhanced (EBEN)
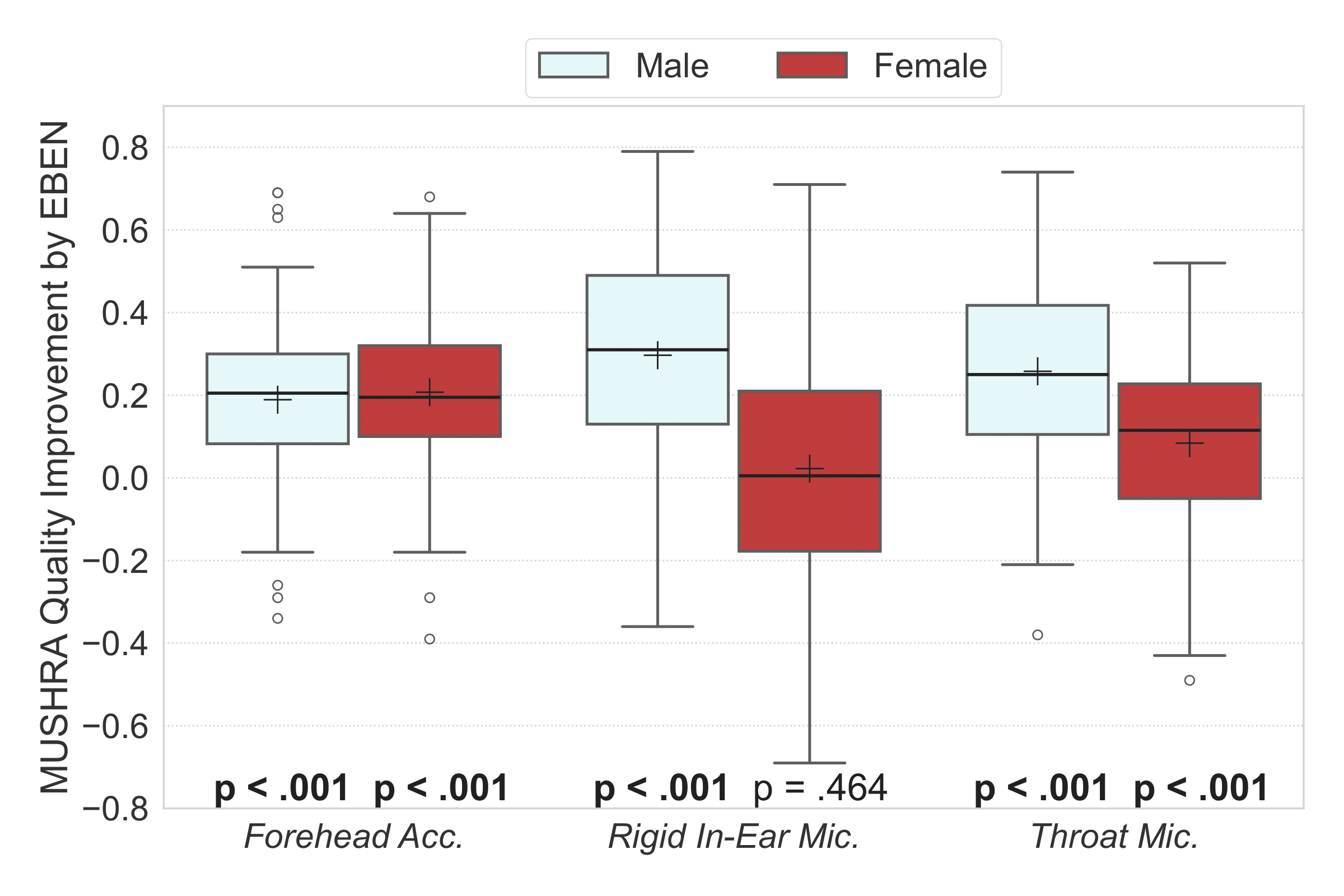
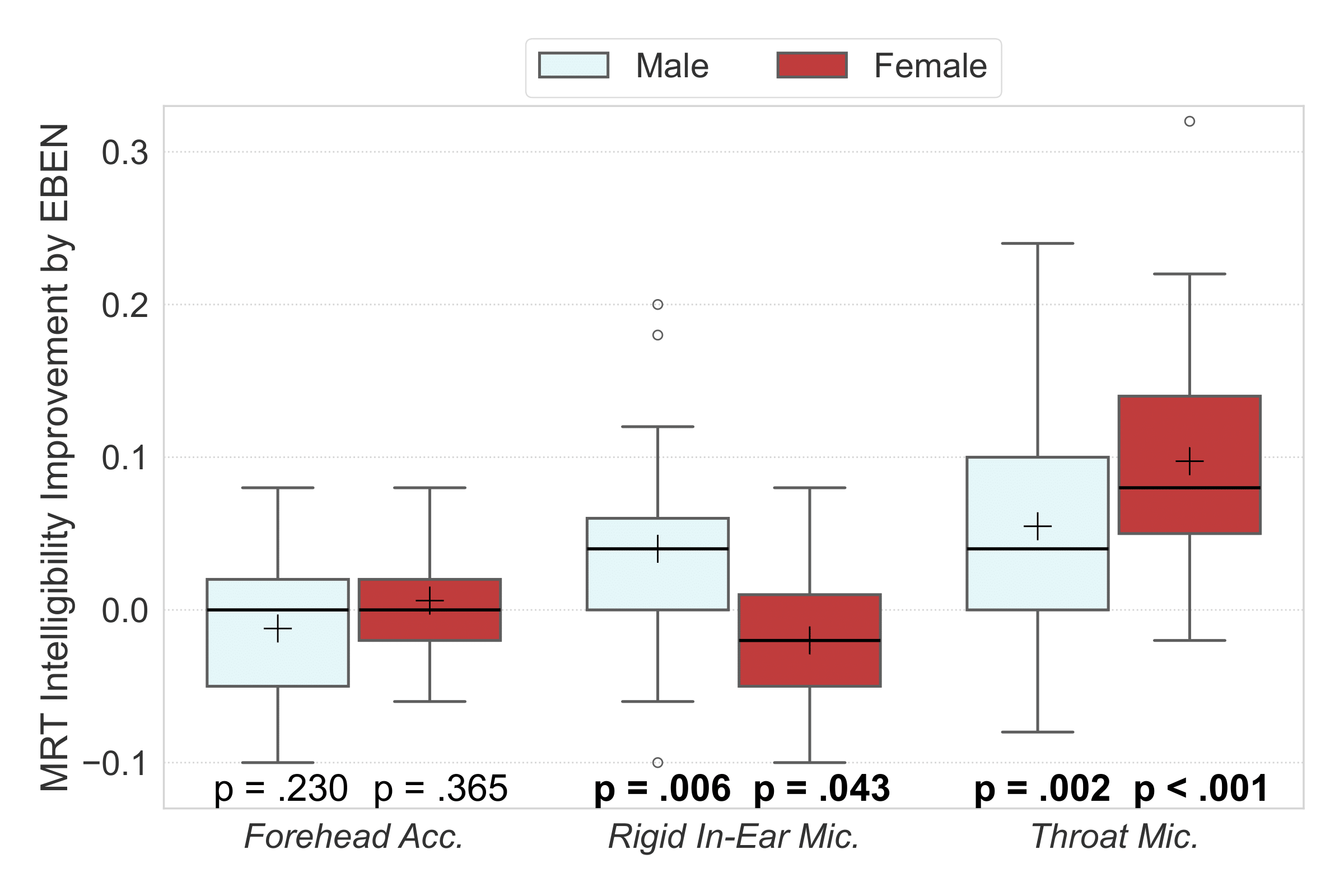
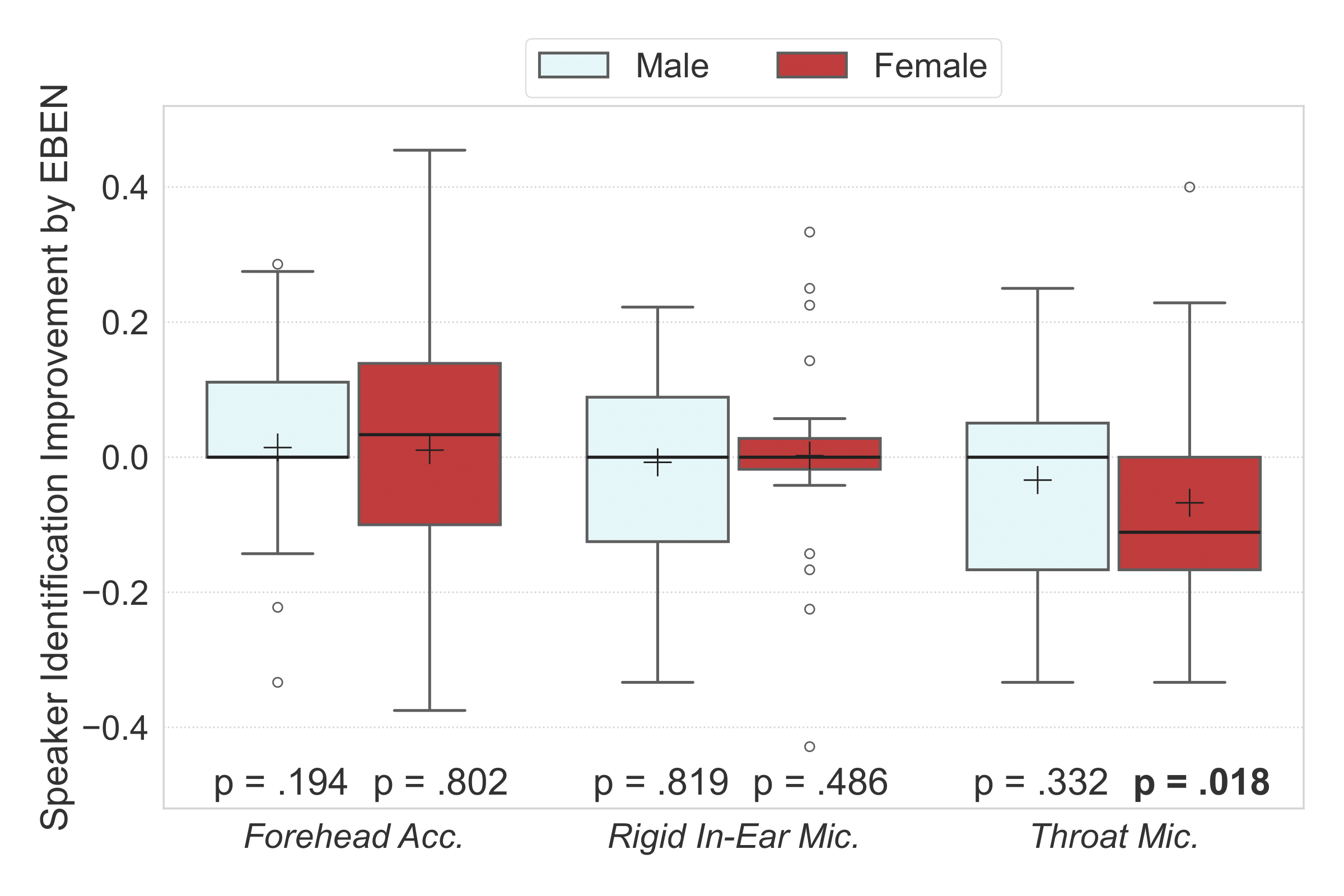
Listening tests for EBEN
Quality
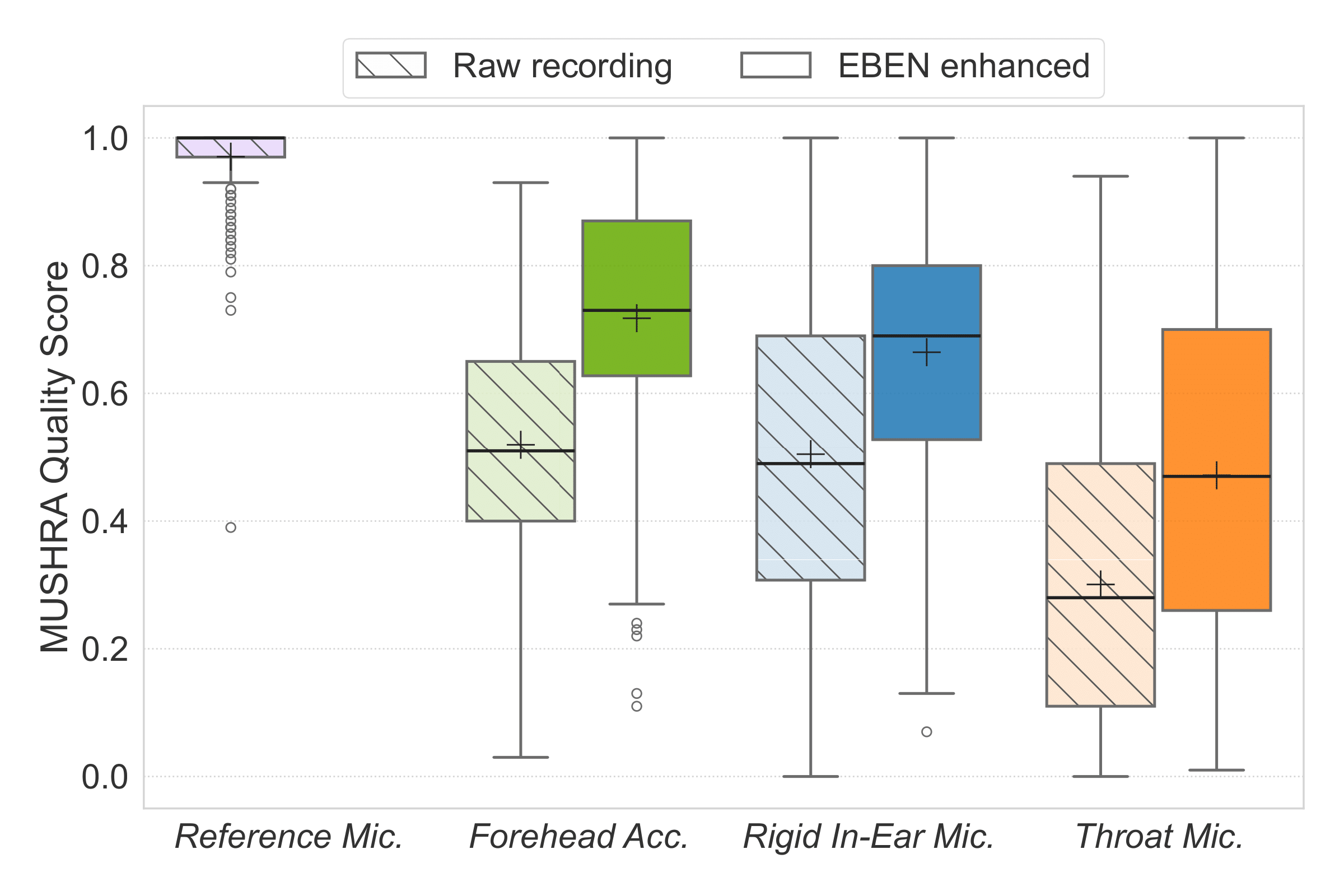
Intelligibility
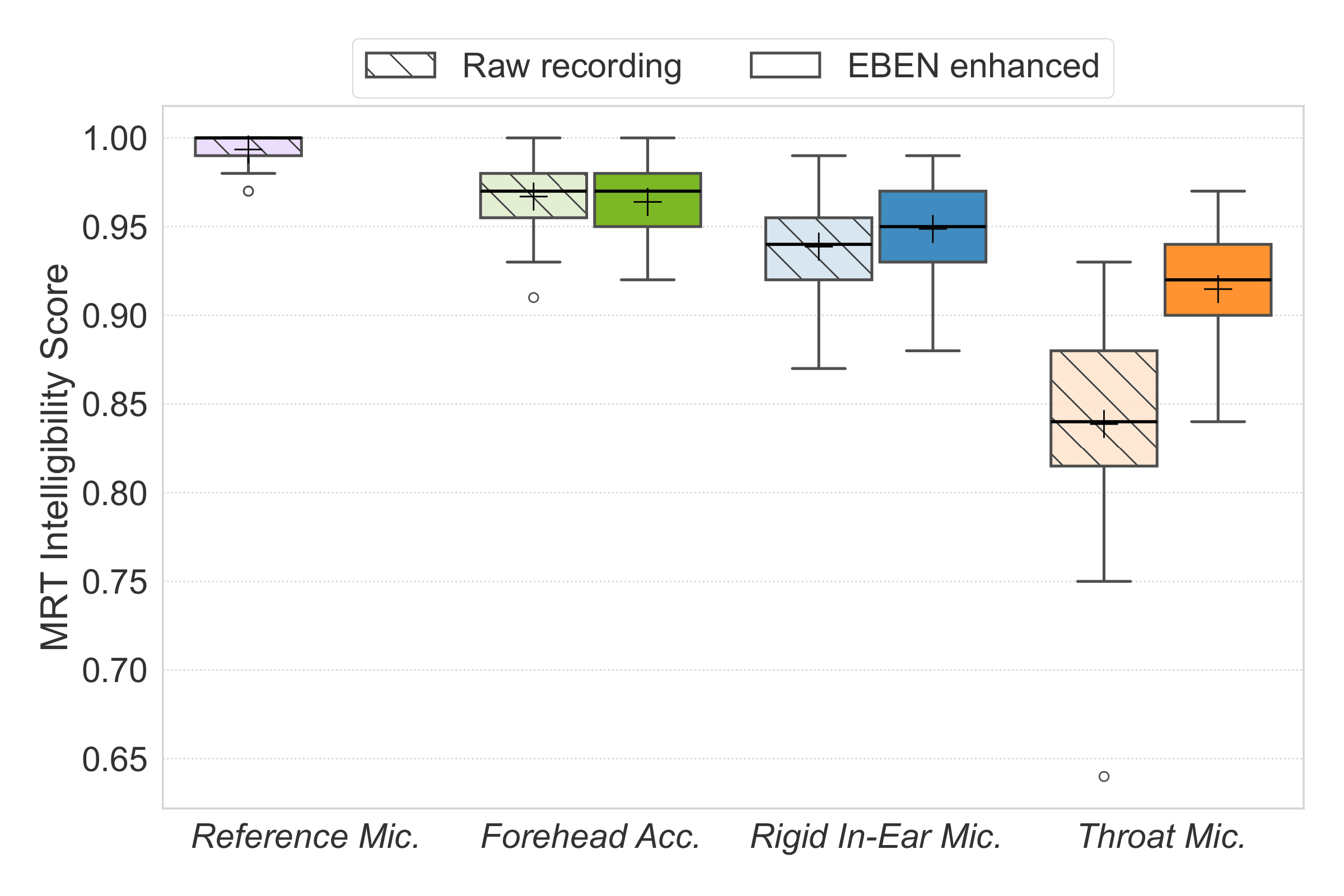
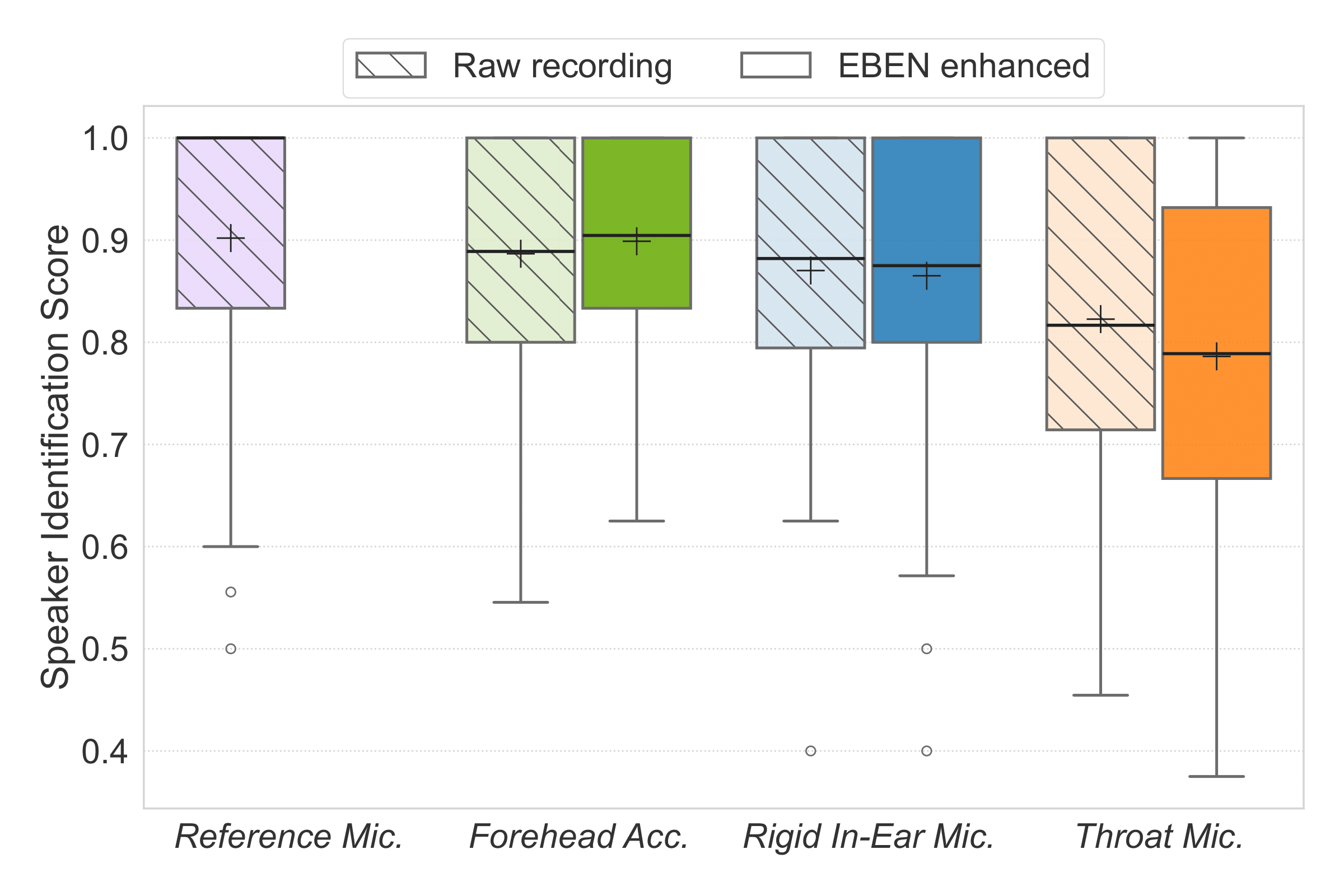
Speaker identity
Comparison with Objective Metrics

Codec-based Speech enhancement
Neural Audio Codecs Timeline
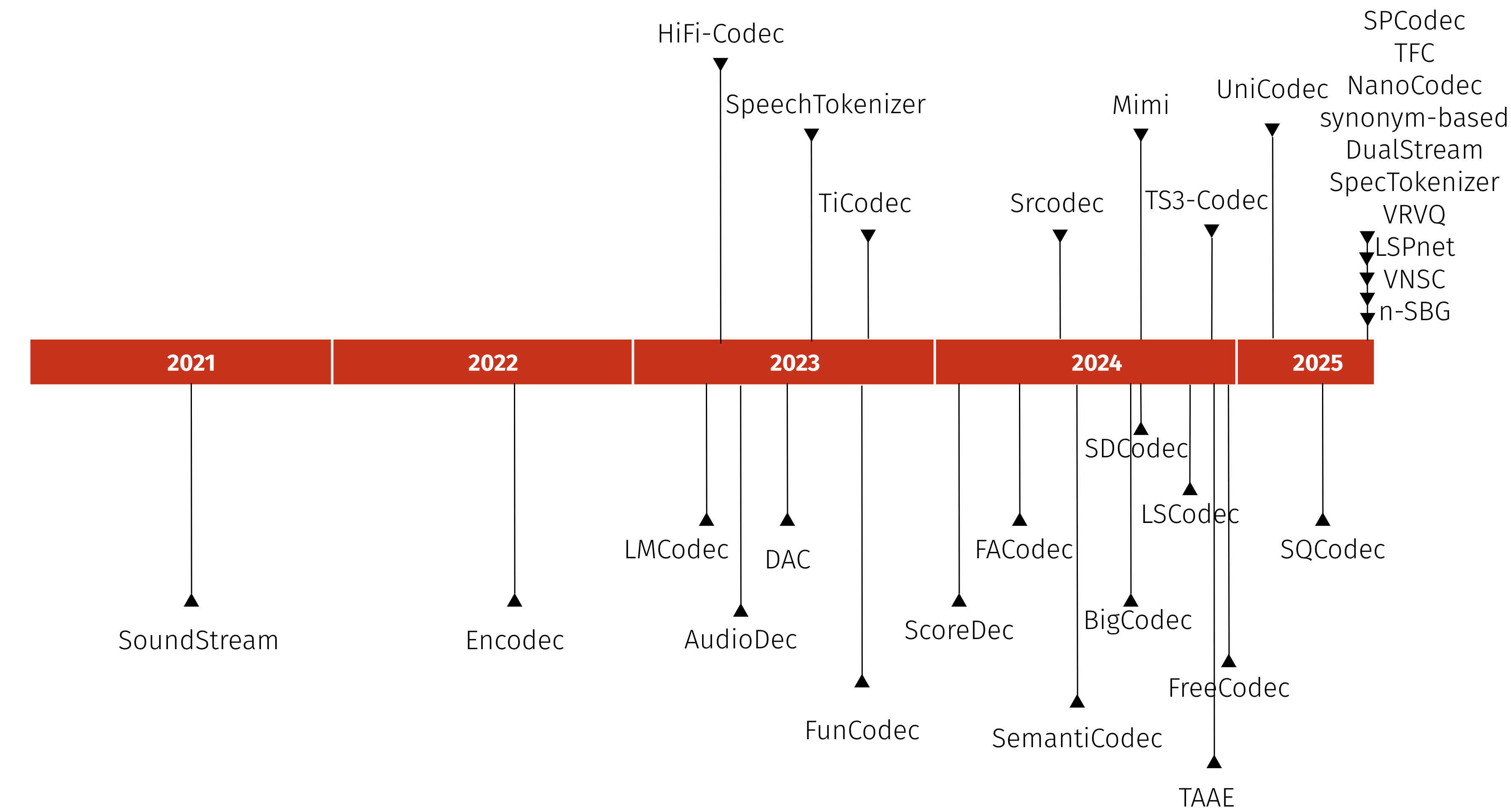
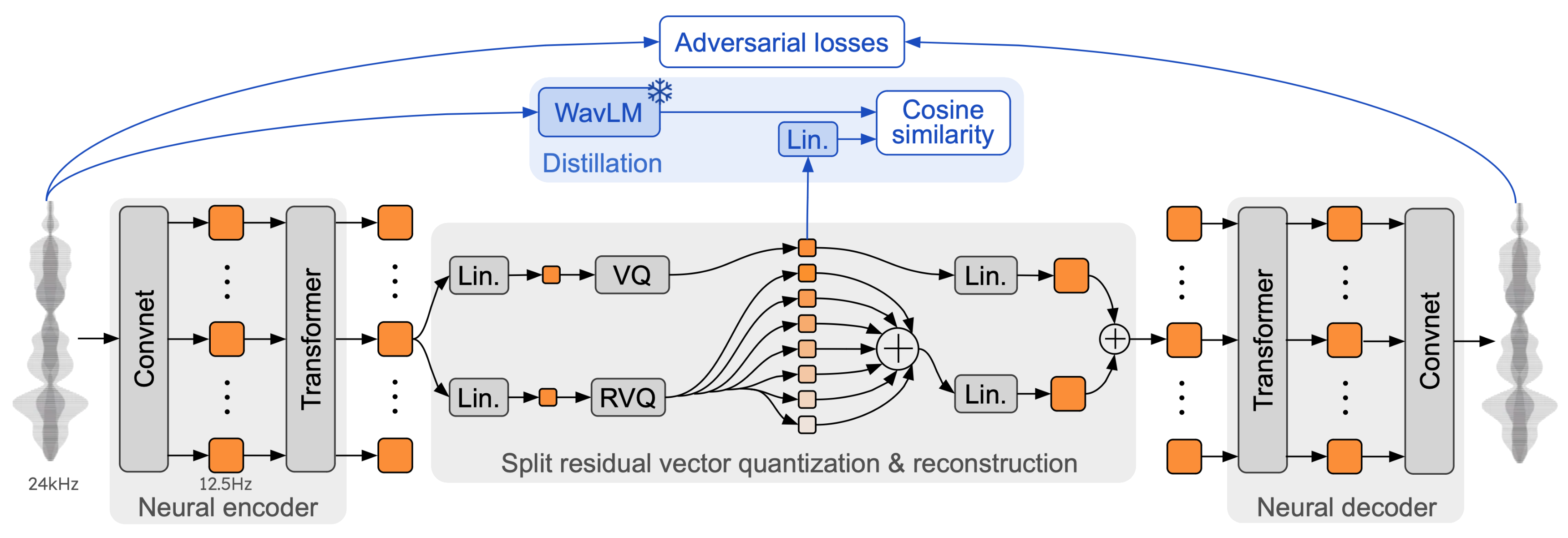
Mimi
My view on Bandwidth extension
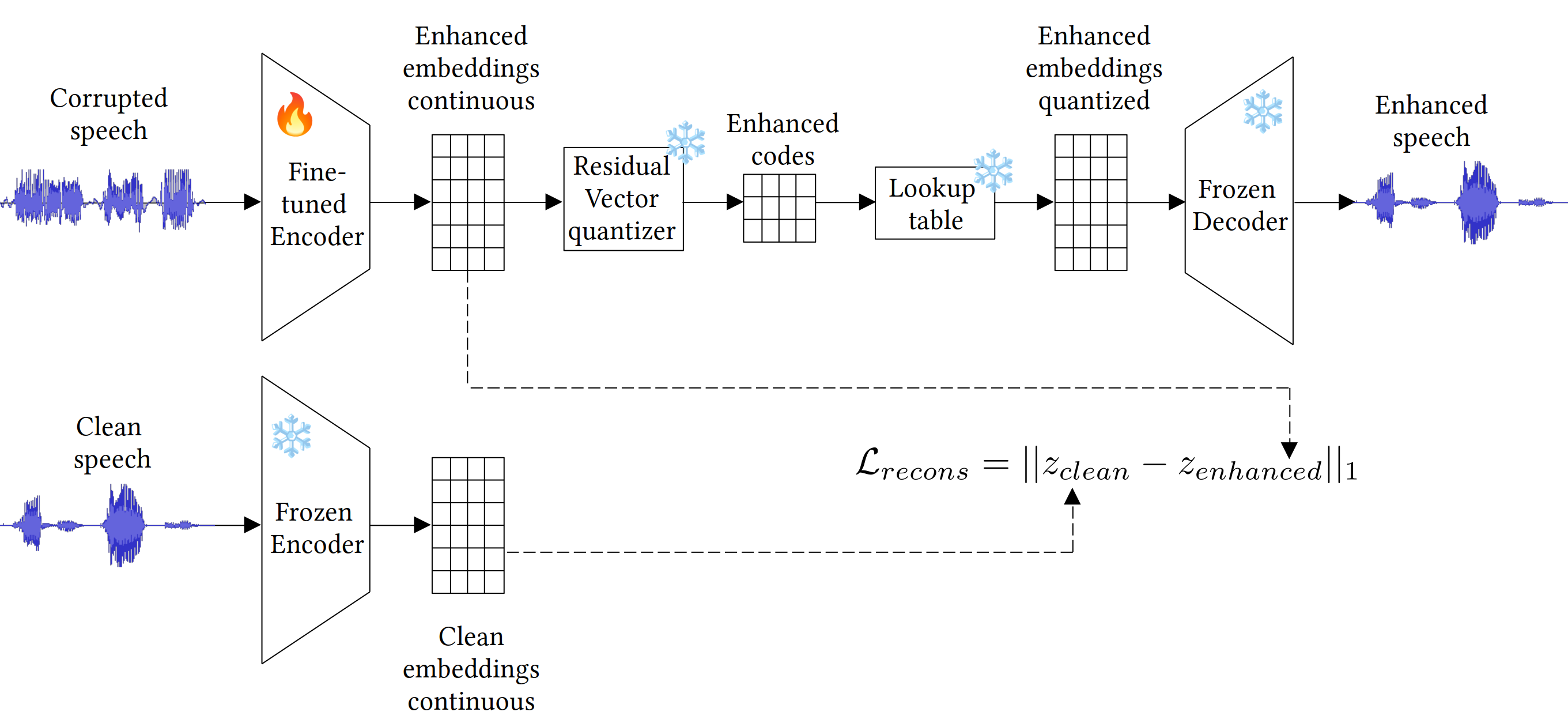
Results on speech-clean for the throat microphone
Qualitative results
| Method | Signal 1 | Signal 2 | Signal 3 | Signal 4 |
|---|---|---|---|---|
| Corrupted | ||||
| Reference | ||||
| EBEN | ||||
| Mimi finetuning | ||||
| NeMo FlowMatching (Ku et al., ICASSP 2025) |
Quantitative results
| Approach | Parameters | eSTOI | Noresqa-MOS | PER | SI-SDR |
|---|---|---|---|---|---|
| Raw Throat | – | 0.67 | 3.10 | 50.8% | –8.0 |
| EBEN | 1.9M | 0.834 | 3.86 | 18.6% | 3.2 |
| Mimi finetuning | 96.2M | 0.841 | 4.11 | 15.1% | 1.37 |
| NeMo FlowMatching (Ku et al., ICASSP 2025) |
430M | 0.822 | 4.39 | 7.6% | 7.3 |
Real-time demo
Real-time demo backup
Conclusion
Deep learning for speech enhancement applied to radio communications using non-conventional sound capture devices
Conclusion
-
EBEN
Extreme Bandwidth Extension Network- Performs joint bandwidth extension and denoising
- Fast inference
- Low memory
-
Vibravox
Dataset of body-conducted speech- 200 participants
- 5 body-conducted microphones
- Diverse noise conditions
- First BCM dataset open sourced on Hugging Face
-
Codec-based speech enhancement
Foundation models for robust processing- Lightweight alternative to LLM-based speech enhancement
- Demo user interface
Contributions
- Vibravox: A Dataset of French Speech Captured with Body-conduction Audio Sensors Hauret J., Olivier M., Joubaud T., Langrenne C., Poirée S., Zimpfer V., Bavu É. — Speech Communication, 2025, p. 103238
- Configurable EBEN: Extreme Bandwidth Extension Network to enhance body-conduction speech capture Hauret J., Bavu É., Joubaud T., Zimpfer V. — IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023, 31:3499–3512
- Bringing Interpretability to Neural Audio Codecs Sadok S., Hauret J. (equal contribution), Bavu É. — Interspeech 2025
- French Listening Tests for the Assessment of Intelligibility, Quality, and Identity of Body-Conducted Speech Enhancement Joubaud T., Hauret J., Zimpfer V., Bavu É. — Interspeech 2025
- EBEN: Extreme bandwidth extension network applied to speech signals captured with noise-resilient microphones Hauret J., Joubaud T., Zimpfer V., Bavu É. — IEEE ICASSP 2023
- Real-time speech enhancement in noise for throat microphone using neural audio codec as foundation model Hauret J., Bavu É. — WASPAA 2025, Demo track
Future Work
- Deploy real-time EBEN on ASICs
- Launch a BCM challenge with Vibravox
- Explore pre-training tasks (e.g., ref→ref with EBEN)
- Combine Vibravox with SOTA simulation methods
- Develop multimodal enhancement (in-ear + out-of-ear mics)
- Align objective metrics with listening tests
Thank you for your attention
julien.hauret@lecnam.net
Questions ?
PQMF TUTO
Why Coherence?
| Measure | Frequency resolution | No Linear assumption | Formula |
|---|---|---|---|
| Coherence | ✅ | ✅ | \(\displaystyle \gamma^2_{xy}(f) = \frac{|S_{xy}(f)|^2}{S_{xx}(f)S_{yy}(f)}\) |
| Transfer function | ✅ | ❌ | \(\displaystyle H(f) = \frac{Y(f)}{X(f)}\) |
| Concordance coefficient | ❌ | ✅ | \(\displaystyle \rho_c = \frac{2\rho\sigma_x\sigma_y}{\sigma_x^2+\sigma_y^2+(\mu_x-\mu_y)^2}\) |
Filterbank Comparison
| Filterbank | Real-valued | Short filter length | No redundancy | No perceptual bias | Easy manipulation |
|---|---|---|---|---|---|
| PQMF (critically sampled) |
✅ | ✅ | ✅ | ✅ | ✅ |
| Paraunitary FIR | ✅ | ❌ | ✅ | ✅ | ❌ |
| Oversampled FB | ✅ | ❌ | ❌ | ✅ | ❌ |
| Non-uniform FB | ✅ | ❌ | ❌ | ❌ | ❌ |
| DFT-modulated | ❌ | ✅ | ✅ | ✅ | ❌ |
Objective metrics
Models trained on in-ear like Librispeech
| Speech | PESQ | SI-SDR | eSTOI | Noresqa-MOS |
|---|---|---|---|---|
| Simulated In-ear | 2.42 | 8.4 | 0.83 | 2.57 |
| Audio U-net | 2.24 | 11.9 | 0.87 | 2.59 |
| Hifi-GAN v3 | 1.32 | -25.1 | 0.78 | 3.70 |
| Streaming Seanet | 2.01 | 11.2 | 0.89 | 3.91 |
| Seanet | 1.92 | 11.1 | 0.89 | 4.25 |
| EBEN (ours) | 2.08 | 10.9 | 0.89 | 4.02 |
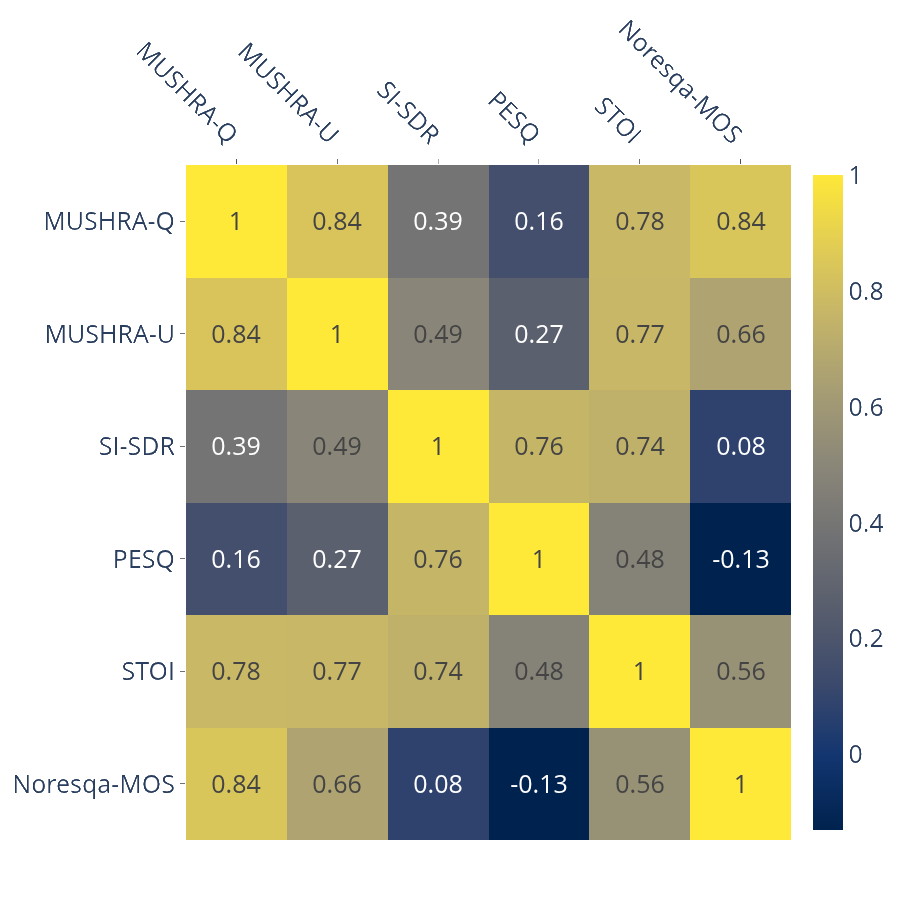
Correlation coefficients of objective and subjective metrics
for simulated in-ear enhancement
silence noise level
silence-mean.JPG
speech-noisy noise level
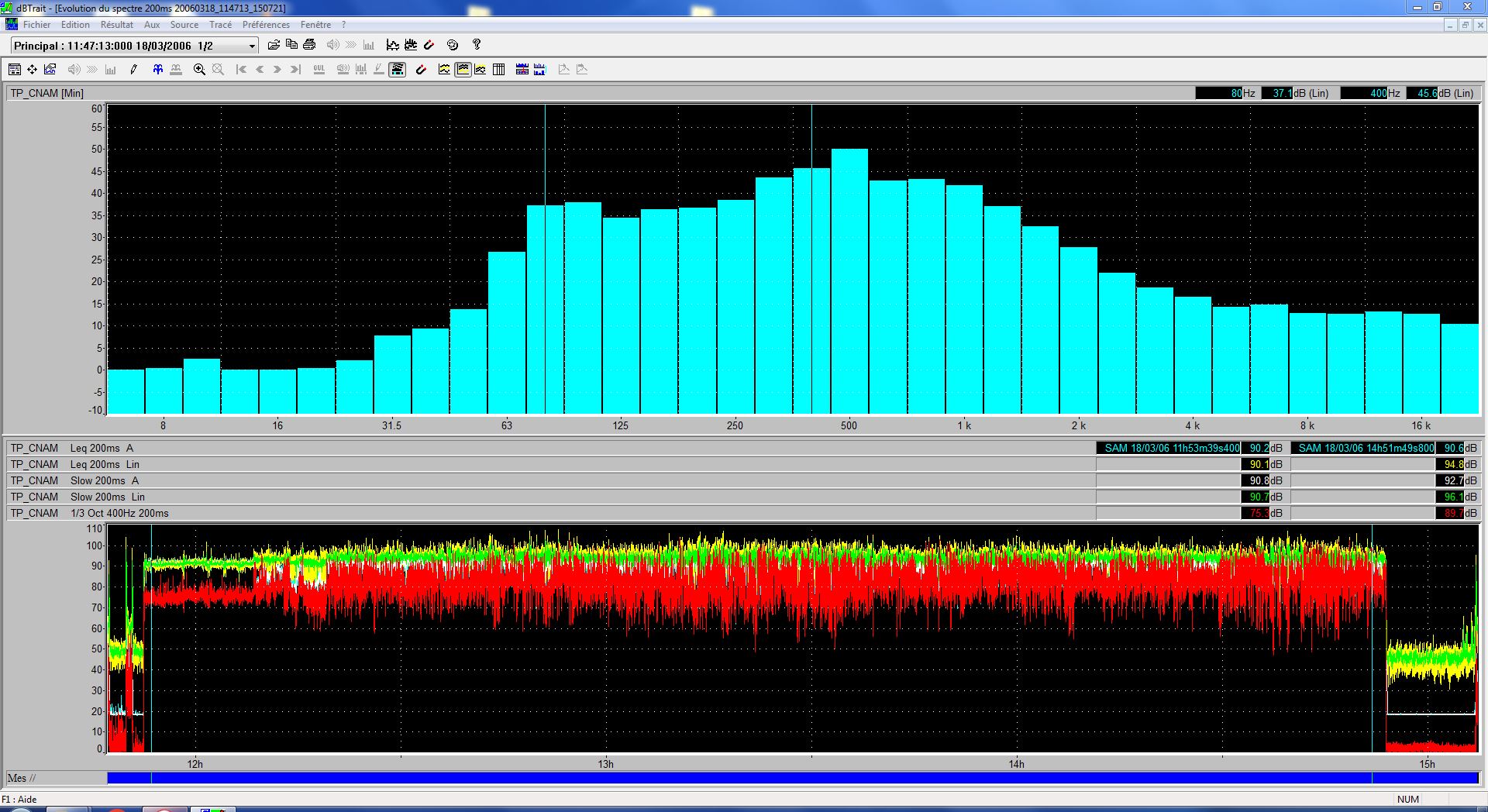
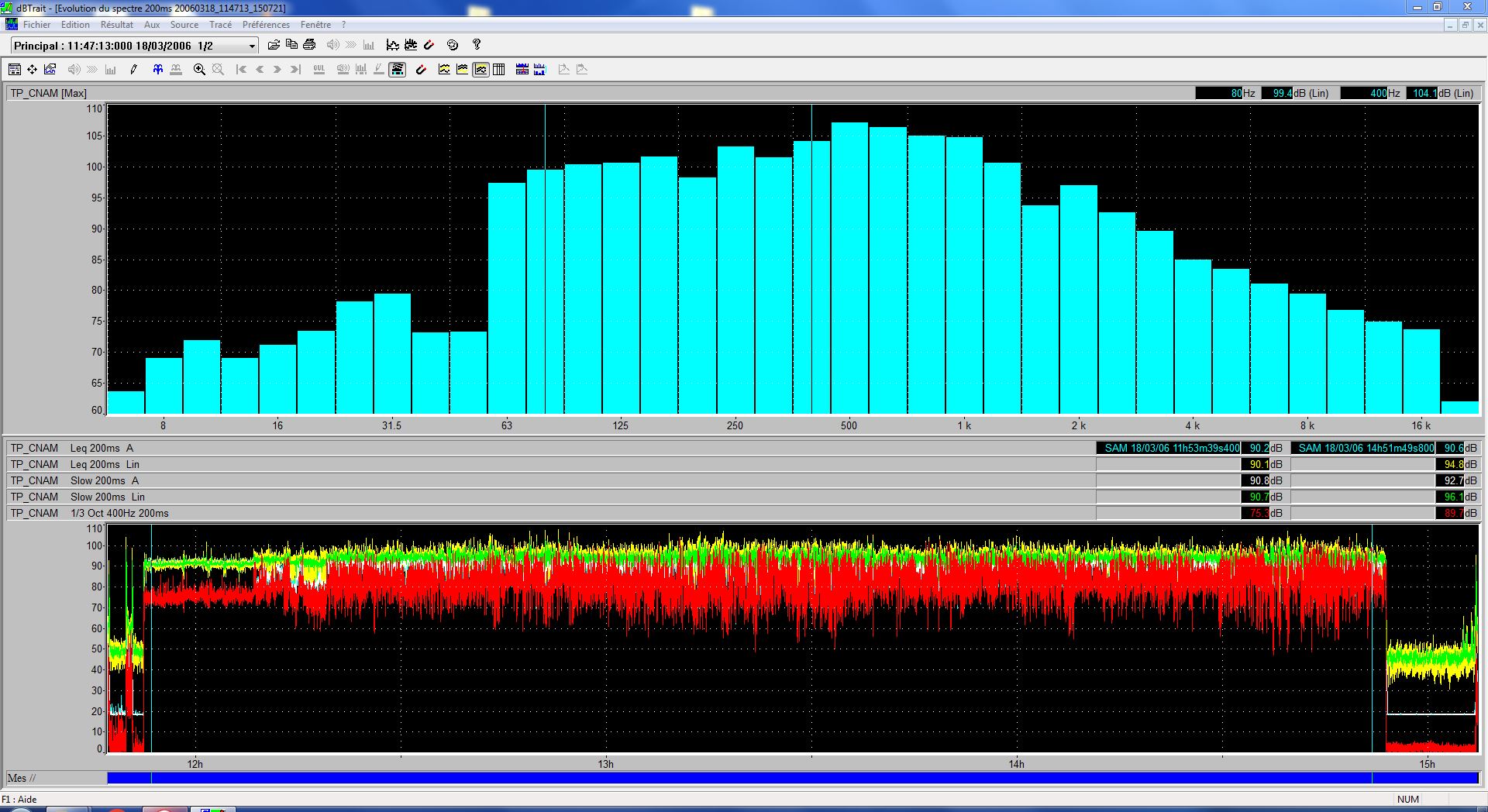
speech-noisy-mean.JPG
speech-noisy-min.JPG
speech-noisy-max.JPG
speechless-noisy noise level
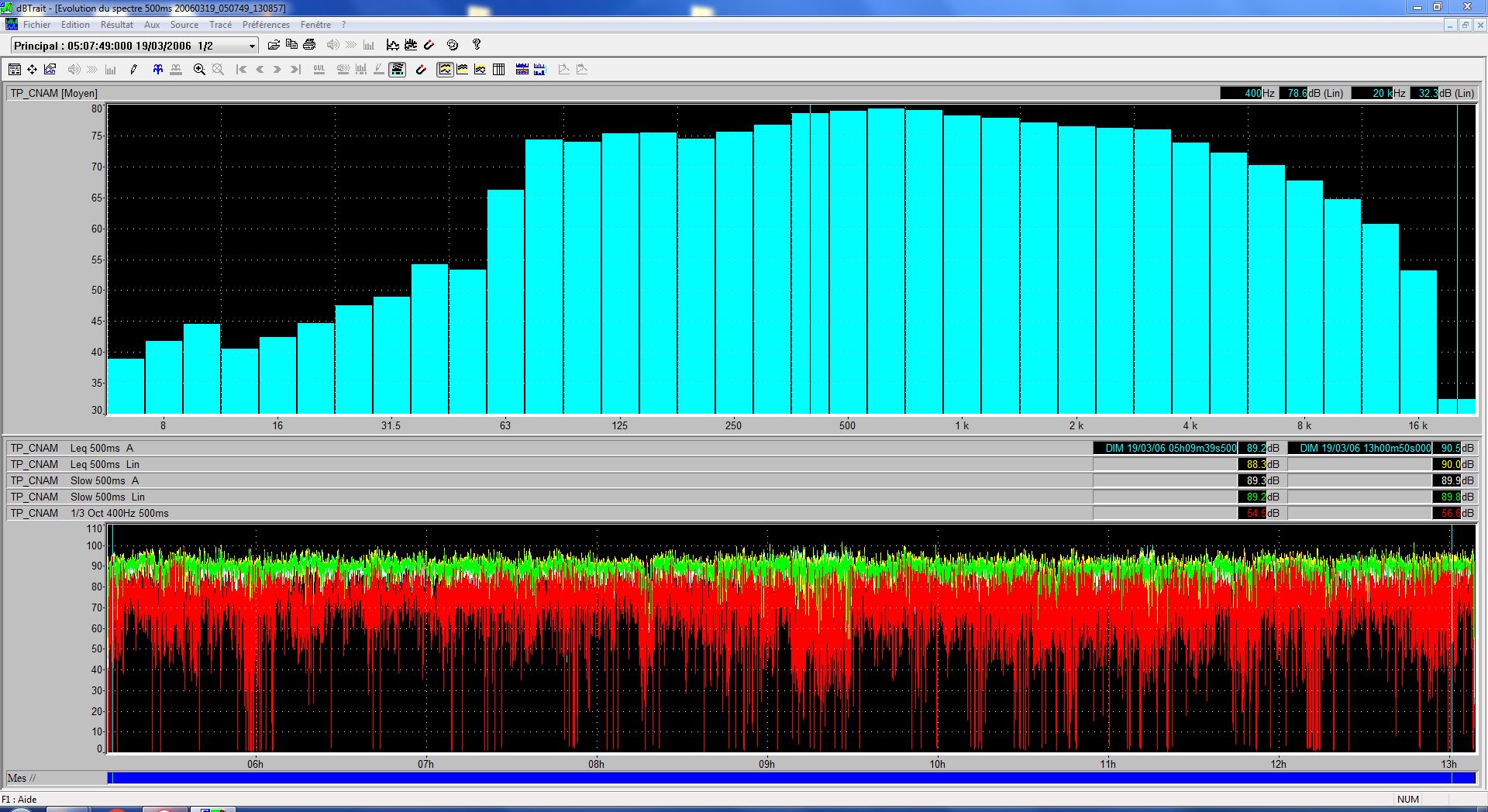
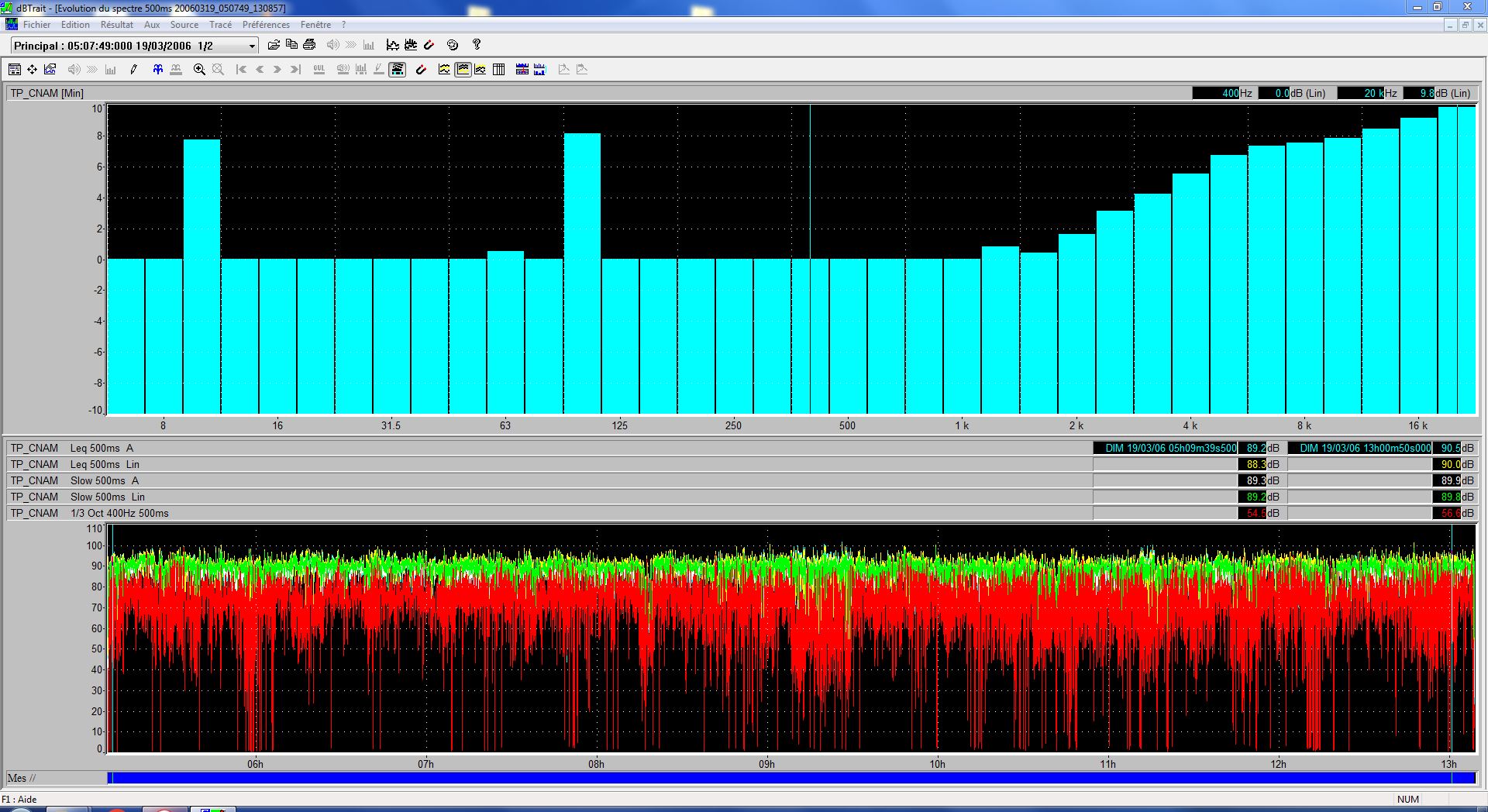
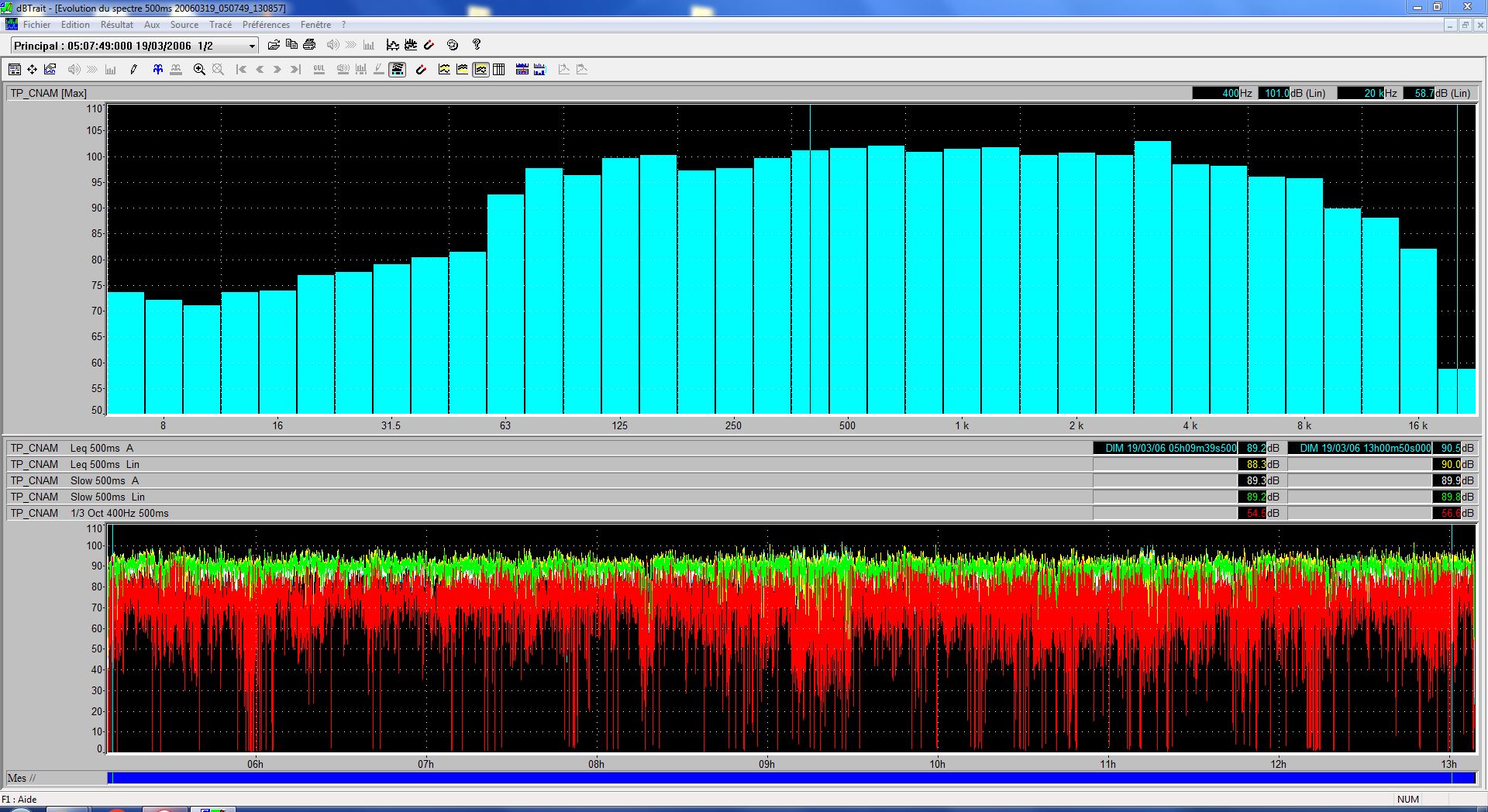
speechless-noisy-mean.JPG
speechless-noisy-min.JPG
speechless-noisy-max.JPG
Median coherences and 25–75% IQR on speech-clean
Forehead

Soft in-ear

Rigid in-ear

Throat

Temple

Mean PSD on all subsets
speechless-clean

speech-clean

speech-noisy

speechless-noisy

Median PSD and 25–75% IQR on speechless-clean
Headset

Forehead

Soft in-ear

Rigid in-ear

Throat

Temple

Median PSD and 25–75% IQR on speech-clean
Headset

Forehead

Soft in-ear

Rigid in-ear

Throat

Temple

Median PSD and 25–75% IQR on speech-noisy
Headset

Forehead

Soft in-ear

Rigid in-ear

Throat

Temple

Median PSD and 25–75% IQR on speechless-noisy
Headset

Forehead

Soft in-ear

Rigid in-ear

Throat

Temple

speech-noisy samples
Noisy headset
Headset enhanced (Sepformer)
Noisy Throat
Throat enhanced (EBEN)
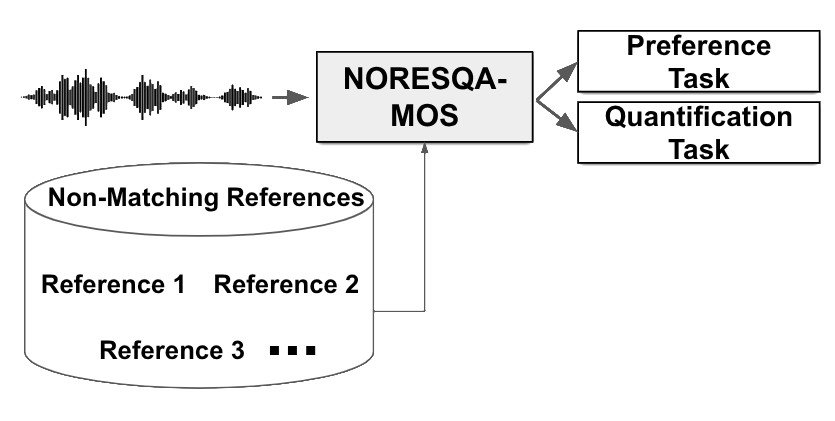
Noresqa-MOS pipeline
Quality
Intelligibility
Speaker identity
Mutual Information (MI) between tokens and speech attributes
librispeech-test-clean
jury deliberation in progress